Hetero-Modal Variational Encoder-Decoder for Joint Modality Completion and Segmentation
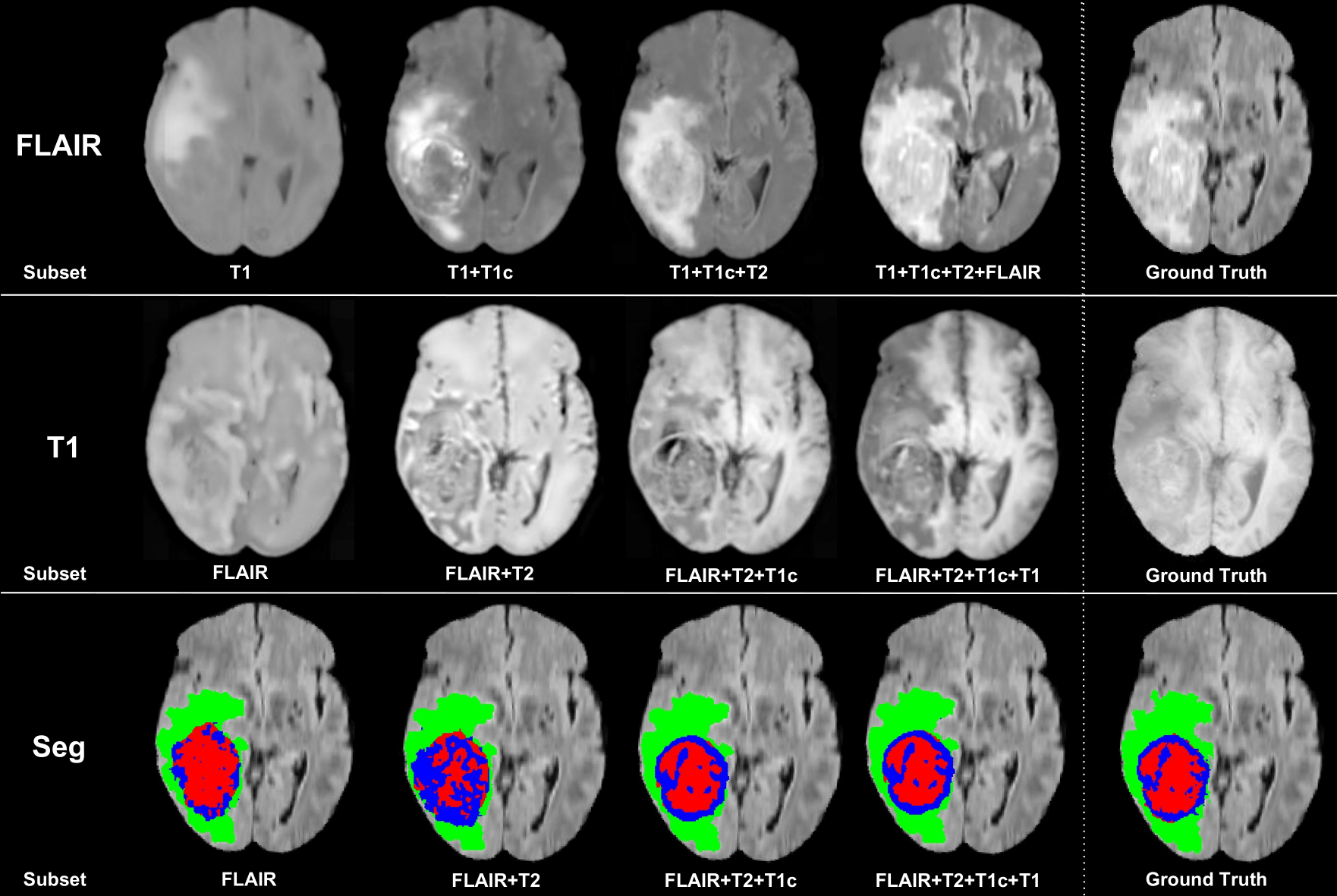
We propose a new deep learning method for tumour segmentation when dealing with missing imaging modalities. Instead of producing one network for each possible subset of observed modalities or using arithmetic operations to combine feature maps, our hetero-modal variational 3D encoder-decoder independently embeds all observed modalities into a shared latent representation. Missing data and tumour segmentation can be then generated from this embedding. In our scenario, the input is a random subset of modalities. We demonstrate that the optimisation problem can be seen as a mixture sampling. In addition to this, we introduce a new network architecture building upon both the 3D U-Net and the Multi-Modal Variational Auto-Encoder (MVAE). Finally, we evaluate our method on BraTS2018 using subsets of the imaging modalities as input. Our model outperforms the current state-of-the-art method for dealing with missing modalities and achieves similar performance to the subset-specific equivalent networks.
PDF Abstract

