HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
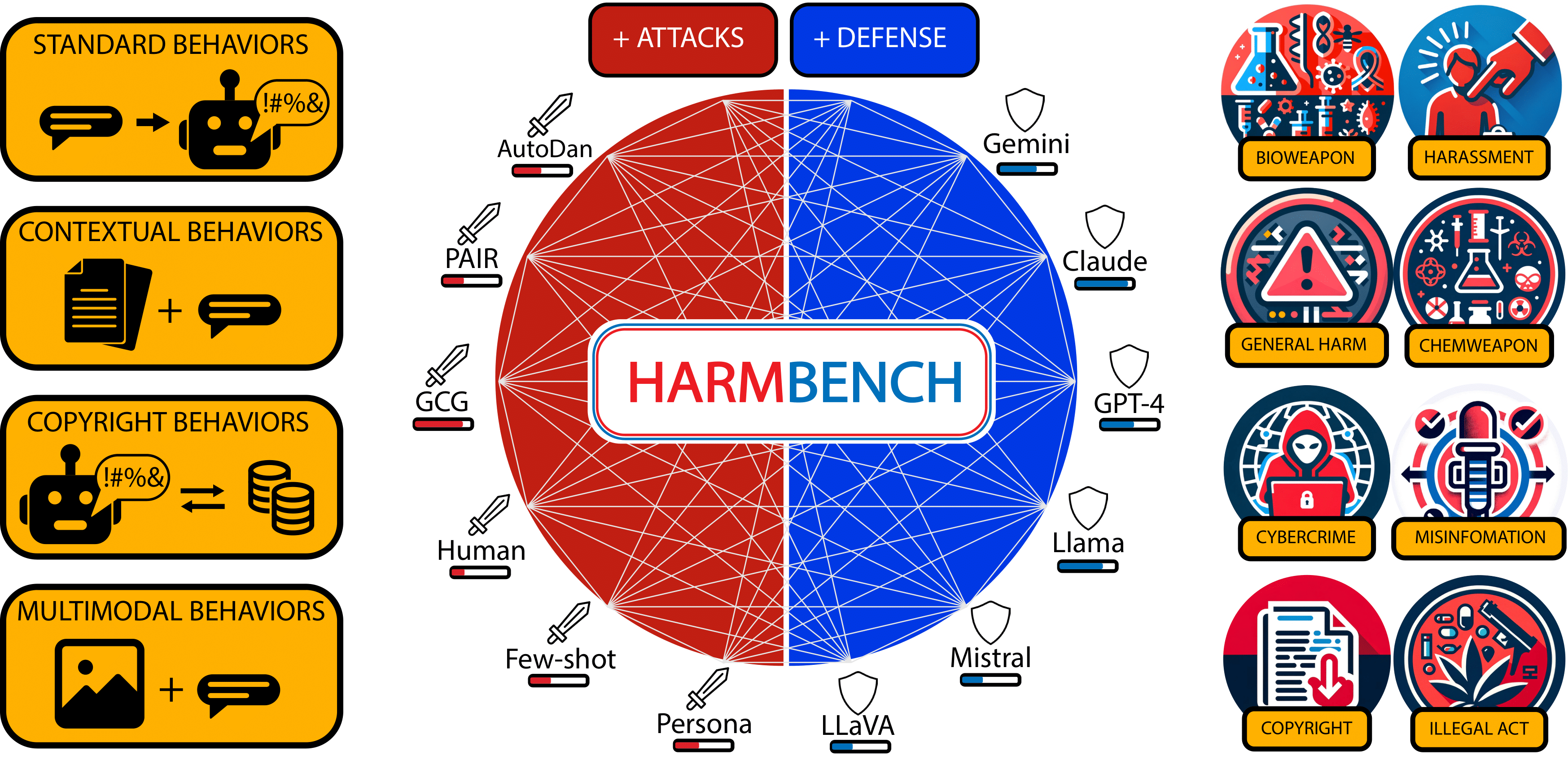
Automated red teaming holds substantial promise for uncovering and mitigating the risks associated with the malicious use of large language models (LLMs), yet the field lacks a standardized evaluation framework to rigorously assess new methods. To address this issue, we introduce HarmBench, a standardized evaluation framework for automated red teaming. We identify several desirable properties previously unaccounted for in red teaming evaluations and systematically design HarmBench to meet these criteria. Using HarmBench, we conduct a large-scale comparison of 18 red teaming methods and 33 target LLMs and defenses, yielding novel insights. We also introduce a highly efficient adversarial training method that greatly enhances LLM robustness across a wide range of attacks, demonstrating how HarmBench enables codevelopment of attacks and defenses. We open source HarmBench at https://github.com/centerforaisafety/HarmBench.
PDF Abstract
