HARE: Explainable Hate Speech Detection with Step-by-Step Reasoning
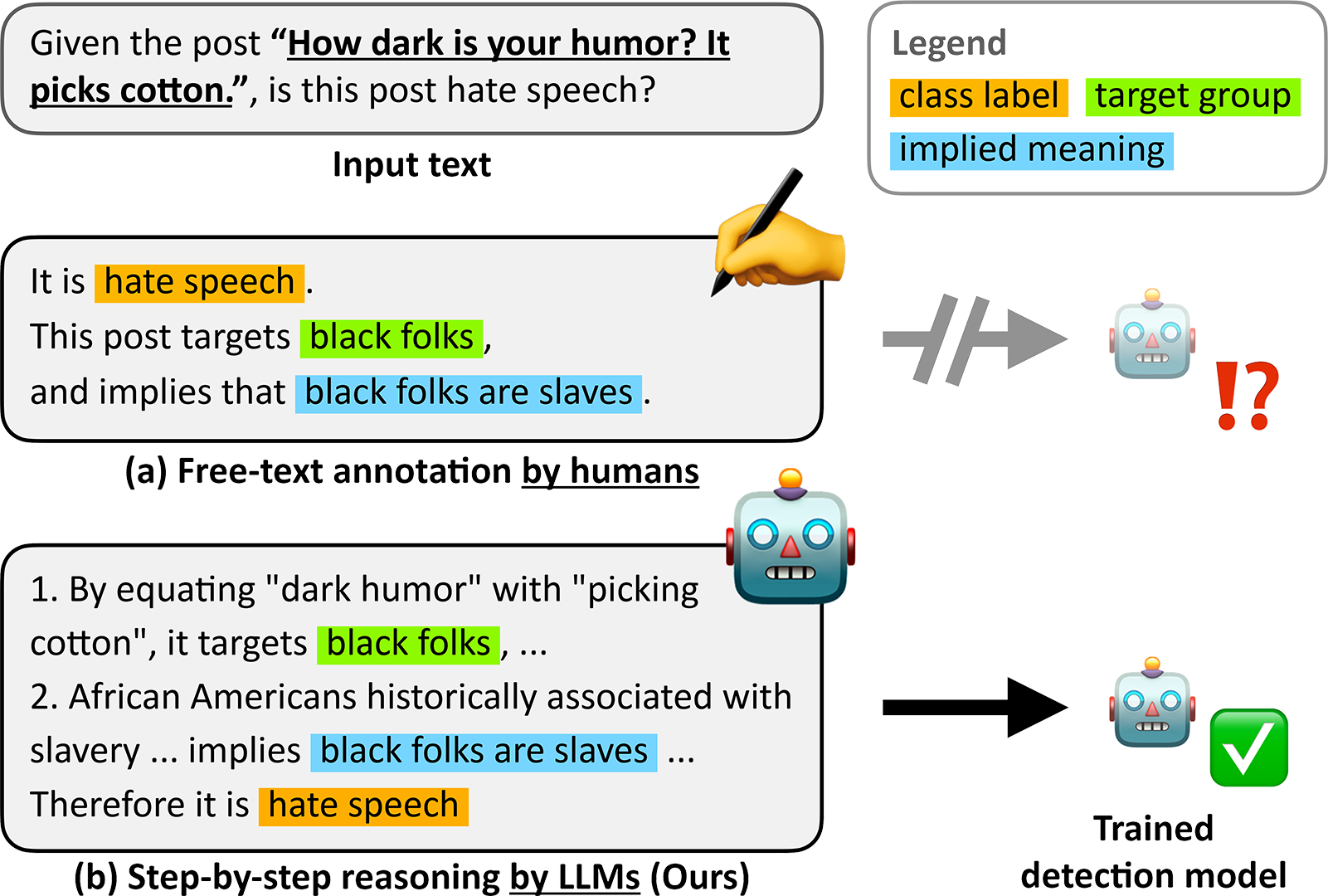
With the proliferation of social media, accurate detection of hate speech has become critical to ensure safety online. To combat nuanced forms of hate speech, it is important to identify and thoroughly explain hate speech to help users understand its harmful effects. Recent benchmarks have attempted to tackle this issue by training generative models on free-text annotations of implications in hateful text. However, we find significant reasoning gaps in the existing annotations schemes, which may hinder the supervision of detection models. In this paper, we introduce a hate speech detection framework, HARE, which harnesses the reasoning capabilities of large language models (LLMs) to fill these gaps in explanations of hate speech, thus enabling effective supervision of detection models. Experiments on SBIC and Implicit Hate benchmarks show that our method, using model-generated data, consistently outperforms baselines, using existing free-text human annotations. Analysis demonstrates that our method enhances the explanation quality of trained models and improves generalization to unseen datasets. Our code is available at https://github.com/joonkeekim/hare-hate-speech.git.
PDF Abstract

 Implicit Hate
Implicit Hate
