Gradient Energy Matching for Distributed Asynchronous Gradient Descent
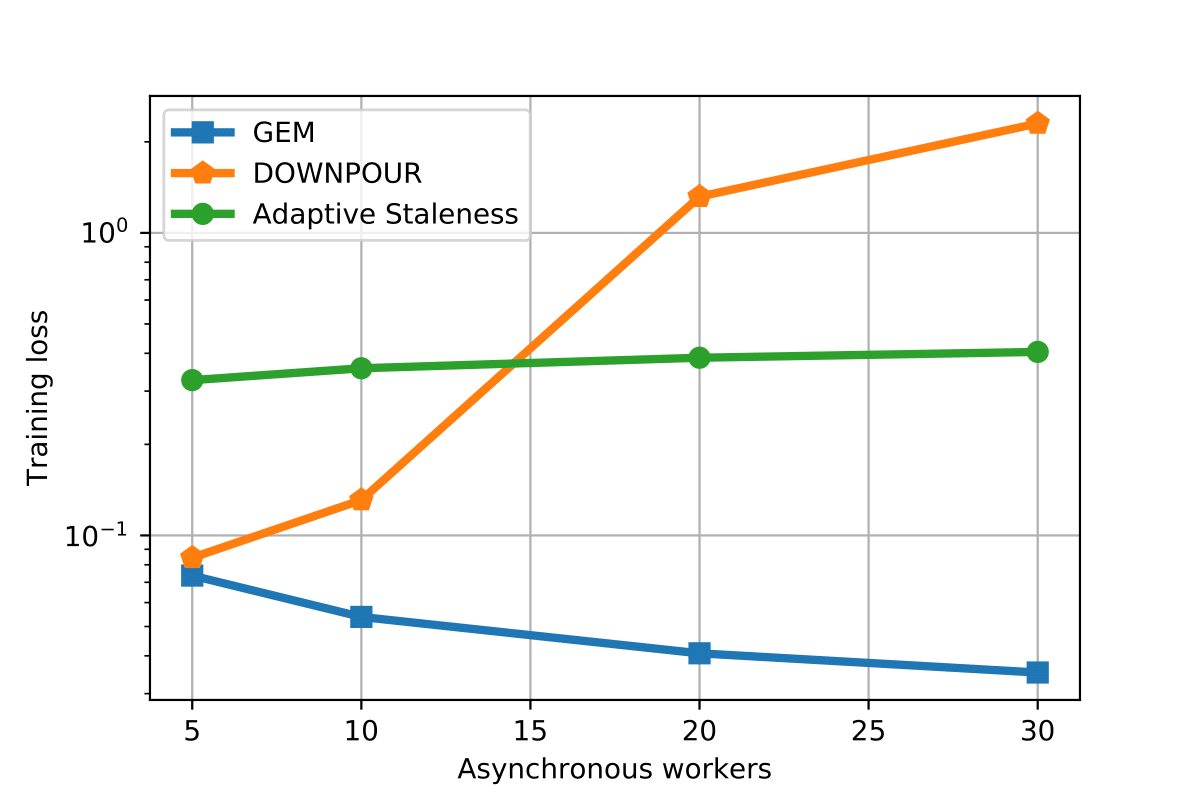
Distributed asynchronous SGD has become widely used for deep learning in large-scale systems, but remains notorious for its instability when increasing the number of workers. In this work, we study the dynamics of distributed asynchronous SGD under the lens of Lagrangian mechanics. Using this description, we introduce the concept of energy to describe the optimization process and derive a sufficient condition ensuring its stability as long as the collective energy induced by the active workers remains below the energy of a target synchronous process. Making use of this criterion, we derive a stable distributed asynchronous optimization procedure, GEM, that estimates and maintains the energy of the asynchronous system below or equal to the energy of sequential SGD with momentum. Experimental results highlight the stability and speedup of GEM compared to existing schemes, even when scaling to one hundred asynchronous workers. Results also indicate better generalization compared to the targeted SGD with momentum.
PDF Abstract

