Gradient boosting for convex cone predict and optimize problems
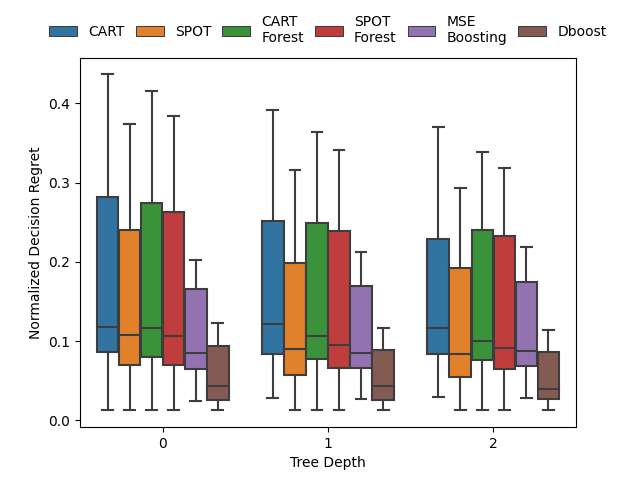
Prediction models are typically optimized independently from decision optimization. A smart predict then optimize (SPO) framework optimizes prediction models to minimize downstream decision regret. In this paper we present dboost, the first general purpose implementation of smart gradient boosting for `predict, then optimize' problems. The framework supports convex quadratic cone programming and gradient boosting is performed by implicit differentiation of a custom fixed-point mapping. Experiments comparing with state-of-the-art SPO methods show that dboost can further reduce out-of-sample decision regret.
PDF AbstractCode
Tasks
Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
