GPT4Vis: What Can GPT-4 Do for Zero-shot Visual Recognition?
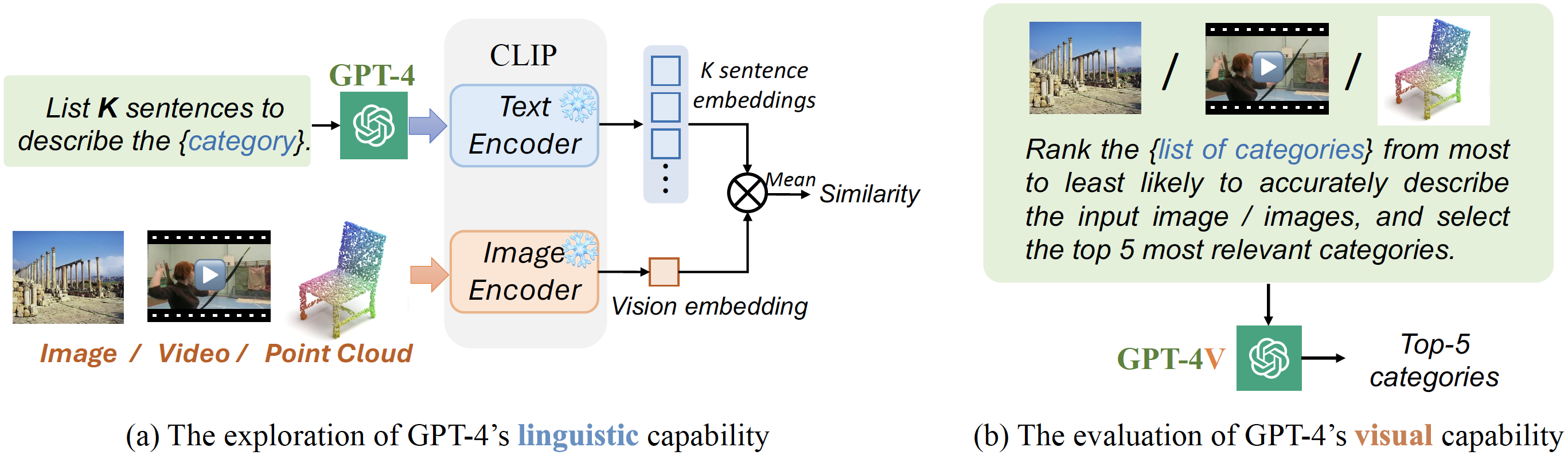
This paper does not present a novel method. Instead, it delves into an essential, yet must-know baseline in light of the latest advancements in Generative Artificial Intelligence (GenAI): the utilization of GPT-4 for visual understanding. Our study centers on the evaluation of GPT-4's linguistic and visual capabilities in zero-shot visual recognition tasks: Firstly, we explore the potential of its generated rich textual descriptions across various categories to enhance recognition performance without any training. Secondly, we evaluate GPT-4's visual proficiency in directly recognizing diverse visual content. We conducted extensive experiments to systematically evaluate GPT-4's performance across images, videos, and point clouds, using 16 benchmark datasets to measure top-1 and top-5 accuracy. Our findings show that GPT-4, enhanced with rich linguistic descriptions, significantly improves zero-shot recognition, offering an average top-1 accuracy increase of 7% across all datasets. GPT-4 excels in visual recognition, outshining OpenAI-CLIP's ViT-L and rivaling EVA-CLIP's ViT-E, particularly in video datasets HMDB-51 and UCF-101, where it leads by 22% and 9%, respectively. We hope this research contributes valuable data points and experience for future studies. We release our code at https://github.com/whwu95/GPT4Vis.
PDF Abstract
 UCF101
UCF101
 ModelNet
ModelNet
 Food-101
Food-101
 FGVC-Aircraft
FGVC-Aircraft
