GOCA: Guided Online Cluster Assignment for Self-Supervised Video Representation Learning
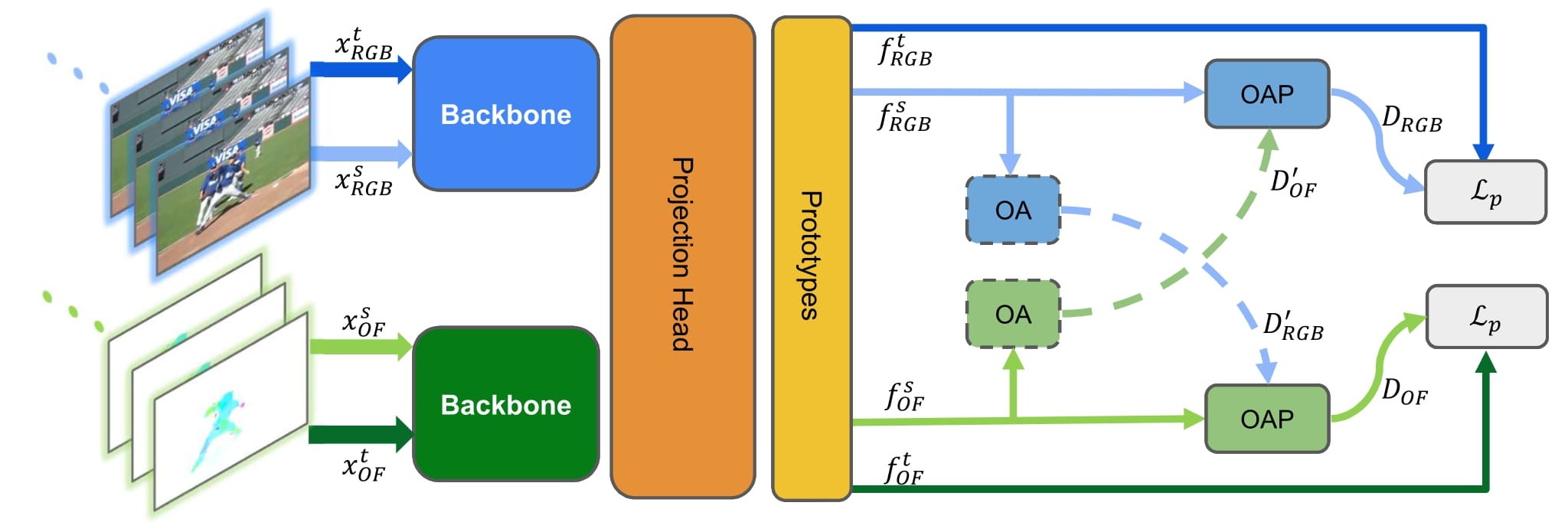
Clustering is a ubiquitous tool in unsupervised learning. Most of the existing self-supervised representation learning methods typically cluster samples based on visually dominant features. While this works well for image-based self-supervision, it often fails for videos, which require understanding motion rather than focusing on background. Using optical flow as complementary information to RGB can alleviate this problem. However, we observe that a naive combination of the two views does not provide meaningful gains. In this paper, we propose a principled way to combine two views. Specifically, we propose a novel clustering strategy where we use the initial cluster assignment of each view as prior to guide the final cluster assignment of the other view. This idea will enforce similar cluster structures for both views, and the formed clusters will be semantically abstract and robust to noisy inputs coming from each individual view. Additionally, we propose a novel regularization strategy to address the feature collapse problem, which is common in cluster-based self-supervised learning methods. Our extensive evaluation shows the effectiveness of our learned representations on downstream tasks, e.g., video retrieval and action recognition. Specifically, we outperform the state of the art by 7% on UCF and 4% on HMDB for video retrieval, and 5% on UCF and 6% on HMDB for video classification
PDF Abstract






 Kinetics
Kinetics
