GIFT: Generative Interpretable Fine-Tuning Transformers
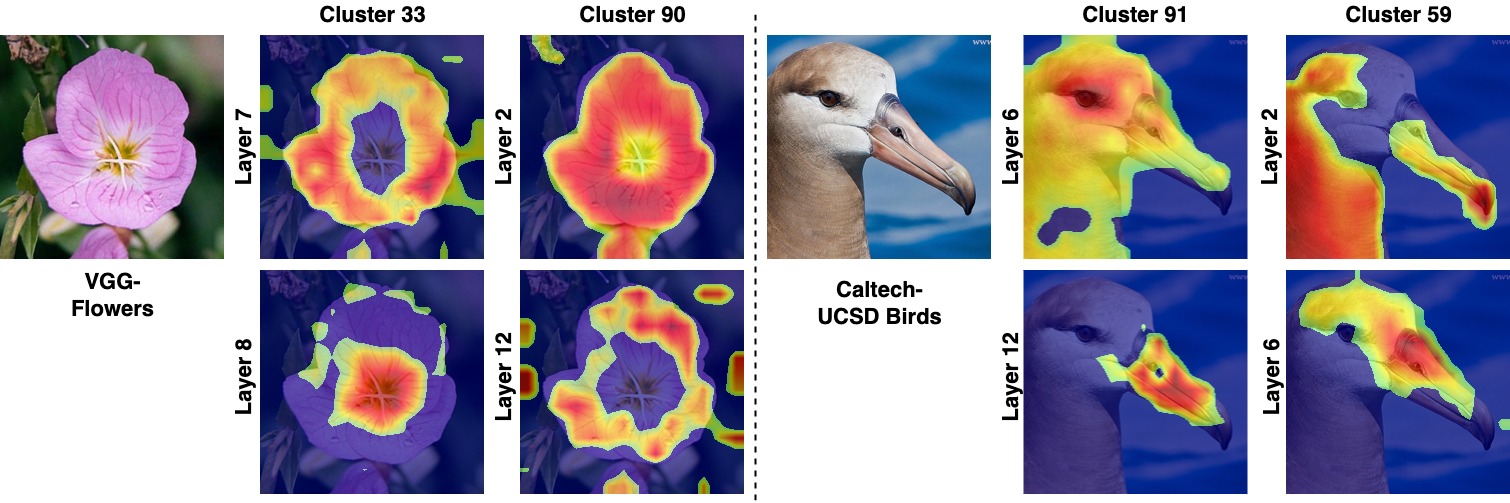
We present GIFT (Generative Interpretable Fine-tuning Transformers) for fine-tuning pretrained (often large) Transformer models at downstream tasks in a parameter-efficient way with built-in interpretability. Our GIFT is a deep parameter-residual learning method, which addresses two problems in fine-tuning a pretrained Transformer model: Where to apply the parameter-efficient fine-tuning (PEFT) to be extremely lightweight yet sufficiently expressive, and How to learn the PEFT to better exploit the knowledge of the pretrained model in a direct way? For the former, we select the final projection (linear) layer in the multi-head self-attention of a Transformer model, and verify its effectiveness. For the latter, in contrast to the prior art that directly introduce new model parameters (often in low-rank approximation form) to be learned in fine-tuning with downstream data, we propose a method for learning to generate the fine-tuning parameters. Our GIFT is a hyper-Transformer which take as input the pretrained parameters of the projection layer to generate its fine-tuning parameters using a proposed Parameter-to-Cluster Attention (PaCa). The PaCa results in a simple clustering-based forward explainer that plays the role of semantic segmentation in testing. In experiments, our proposed GIFT is tested on the VTAB benchmark and the fine-grained visual classification (FGVC) benchmark. It obtains significantly better performance than the prior art. Our code is available at https://github.com/savadikarc/gift
PDF Abstract

 ImageNet
ImageNet
 Oxford 102 Flower
Oxford 102 Flower
 NABirds
NABirds
