Generating Visually Aligned Sound from Videos
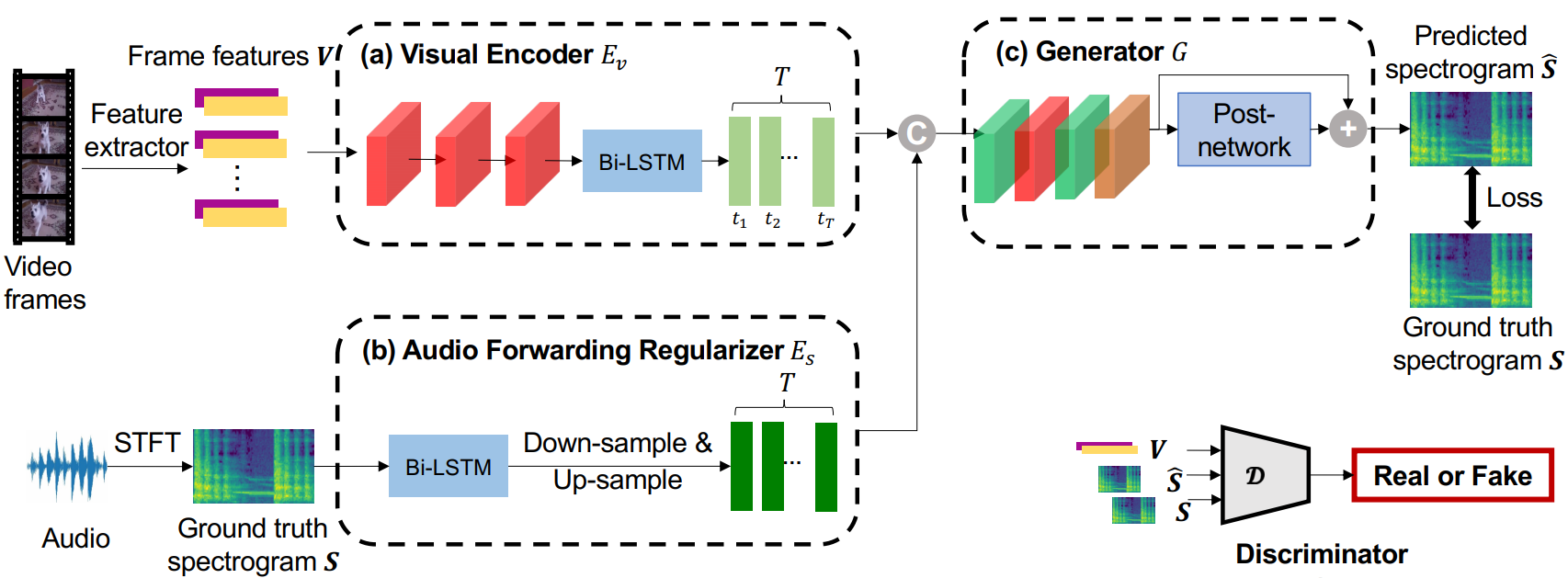
We focus on the task of generating sound from natural videos, and the sound should be both temporally and content-wise aligned with visual signals. This task is extremely challenging because some sounds generated \emph{outside} a camera can not be inferred from video content. The model may be forced to learn an incorrect mapping between visual content and these irrelevant sounds. To address this challenge, we propose a framework named REGNET. In this framework, we first extract appearance and motion features from video frames to better distinguish the object that emits sound from complex background information. We then introduce an innovative audio forwarding regularizer that directly considers the real sound as input and outputs bottlenecked sound features. Using both visual and bottlenecked sound features for sound prediction during training provides stronger supervision for the sound prediction. The audio forwarding regularizer can control the irrelevant sound component and thus prevent the model from learning an incorrect mapping between video frames and sound emitted by the object that is out of the screen. During testing, the audio forwarding regularizer is removed to ensure that REGNET can produce purely aligned sound only from visual features. Extensive evaluations based on Amazon Mechanical Turk demonstrate that our method significantly improves both temporal and content-wise alignment. Remarkably, our generated sound can fool the human with a 68.12% success rate. Code and pre-trained models are publicly available at https://github.com/PeihaoChen/regnet
PDF Abstract
