General surgery vision transformer: A video pre-trained foundation model for general surgery
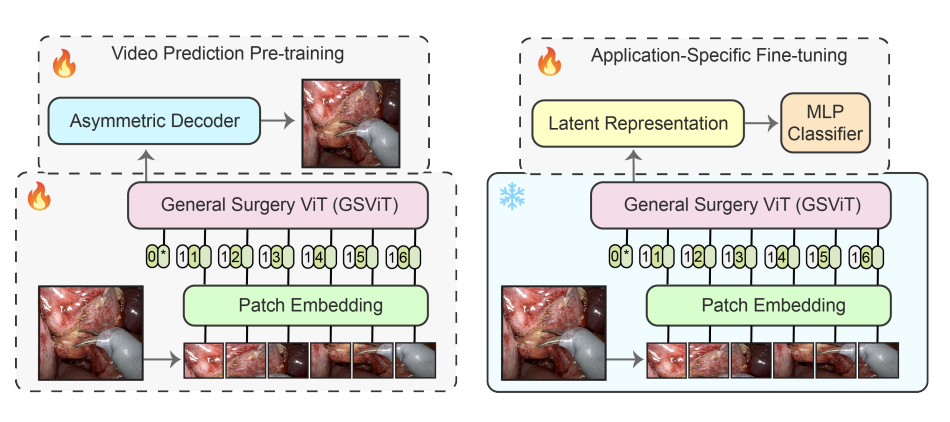
The absence of openly accessible data and specialized foundation models is a major barrier for computational research in surgery. Toward this, (i) we open-source the largest dataset of general surgery videos to-date, consisting of 680 hours of surgical videos, including data from robotic and laparoscopic techniques across 28 procedures; (ii) we propose a technique for video pre-training a general surgery vision transformer (GSViT) on surgical videos based on forward video prediction that can run in real-time for surgical applications, toward which we open-source the code and weights of GSViT; (iii) we also release code and weights for procedure-specific fine-tuned versions of GSViT across 10 procedures; (iv) we demonstrate the performance of GSViT on the Cholec80 phase annotation task, displaying improved performance over state-of-the-art single frame predictors.
PDF Abstract

 Cholec80
Cholec80
