Gen-LaneNet: A Generalized and Scalable Approach for 3D Lane Detection
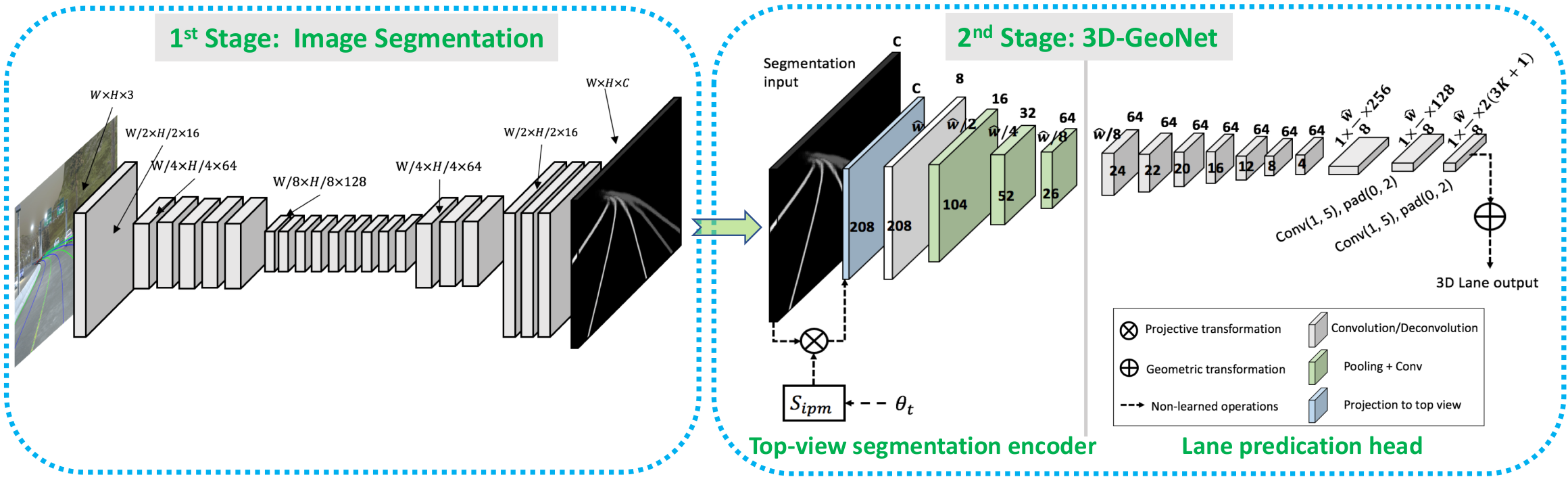
We present a generalized and scalable method, called Gen-LaneNet, to detect 3D lanes from a single image. The method, inspired by the latest state-of-the-art 3D-LaneNet, is a unified framework solving image encoding, spatial transform of features and 3D lane prediction in a single network. However, we propose unique designs for Gen-LaneNet in two folds. First, we introduce a new geometry-guided lane anchor representation in a new coordinate frame and apply a specific geometric transformation to directly calculate real 3D lane points from the network output. We demonstrate that aligning the lane points with the underlying top-view features in the new coordinate frame is critical towards a generalized method in handling unfamiliar scenes. Second, we present a scalable two-stage framework that decouples the learning of image segmentation subnetwork and geometry encoding subnetwork. Compared to 3D-LaneNet, the proposed Gen-LaneNet drastically reduces the amount of 3D lane labels required to achieve a robust solution in real-world application. Moreover, we release a new synthetic dataset and its construction strategy to encourage the development and evaluation of 3D lane detection methods. In experiments, we conduct extensive ablation study to substantiate the proposed Gen-LaneNet significantly outperforms 3D-LaneNet in average precision(AP) and F-score.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract




 3D Lane Synthetic Dataset
3D Lane Synthetic Dataset
 OpenLane
OpenLane

