Gen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising
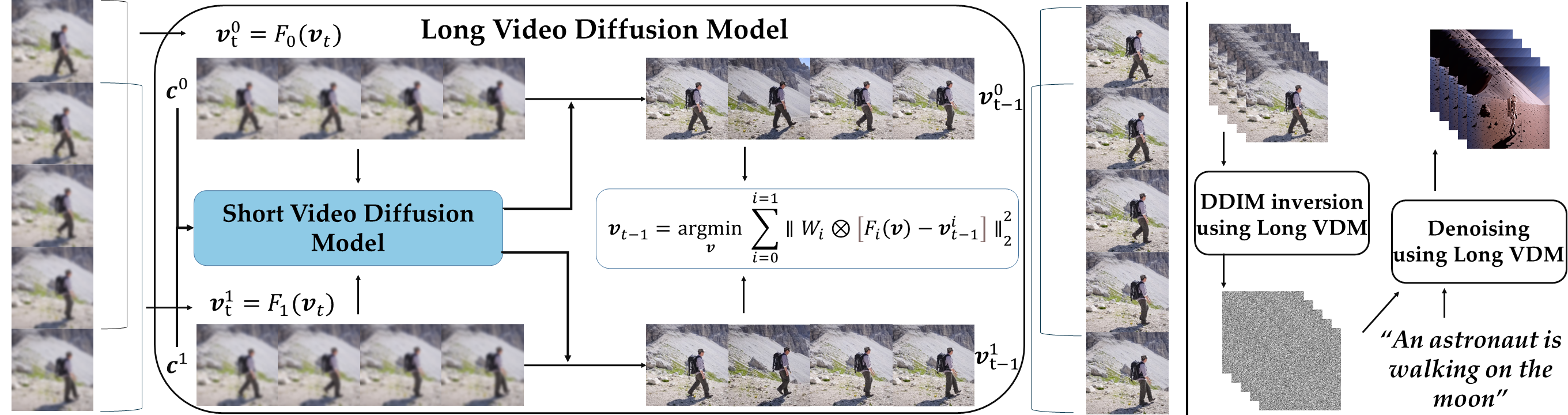
Leveraging large-scale image-text datasets and advancements in diffusion models, text-driven generative models have made remarkable strides in the field of image generation and editing. This study explores the potential of extending the text-driven ability to the generation and editing of multi-text conditioned long videos. Current methodologies for video generation and editing, while innovative, are often confined to extremely short videos (typically less than 24 frames) and are limited to a single text condition. These constraints significantly limit their applications given that real-world videos usually consist of multiple segments, each bearing different semantic information. To address this challenge, we introduce a novel paradigm dubbed as Gen-L-Video, capable of extending off-the-shelf short video diffusion models for generating and editing videos comprising hundreds of frames with diverse semantic segments without introducing additional training, all while preserving content consistency. We have implemented three mainstream text-driven video generation and editing methodologies and extended them to accommodate longer videos imbued with a variety of semantic segments with our proposed paradigm. Our experimental outcomes reveal that our approach significantly broadens the generative and editing capabilities of video diffusion models, offering new possibilities for future research and applications. The code is available at https://github.com/G-U-N/Gen-L-Video.
PDF Abstract Colab
Colab





