G-SPEED: General SParse Efficient Editing MoDel
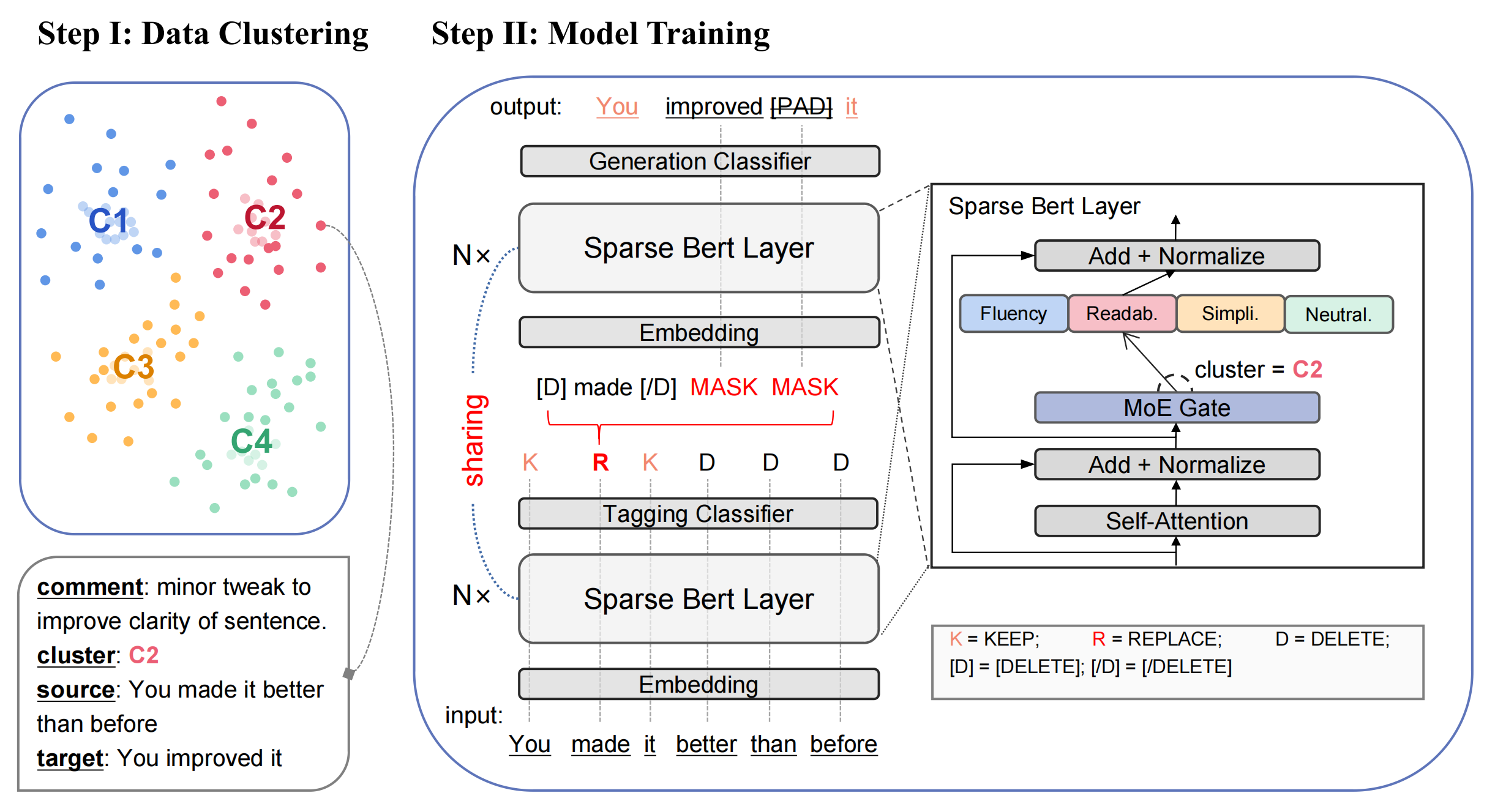
Large Language Models~(LLMs) have demonstrated incredible capabilities in understanding, generating, and manipulating languages. Through human-model interactions, LLMs can automatically understand human-issued instructions and output the expected contents, which can significantly increase working efficiency. In various types of real-world demands, editing-oriented tasks account for a considerable proportion, which involves an interactive process that entails the continuous refinement of existing texts to meet specific criteria. Due to the need for multi-round human-model interaction and the generation of complicated editing tasks, there is an emergent need for efficient general editing models. In this paper, we propose \underline{\textbf{G}}eneral \underline{\textbf{SP}}arse \underline{\textbf{E}}fficient \underline{\textbf{E}}diting Mo\underline{\textbf{D}}el~(\textbf{G-SPEED}), which can fulfill diverse editing requirements through a single model while maintaining low computational costs. Specifically, we first propose a novel unsupervised text editing data clustering algorithm to deal with the data scarcity problem. Subsequently, we introduce a sparse editing model architecture to mitigate the inherently limited learning capabilities of small language models. The experimental outcomes indicate that G-SPEED, with its 508M parameters, can surpass LLMs equipped with 175B parameters. Our code and model checkpoints are available at \url{https://github.com/Banner-Z/G-SPEED}.
PDF Abstract
 GLUE
GLUE
 JFLEG
JFLEG
 ASSET
ASSET
