Fully Attentional Networks with Self-emerging Token Labeling
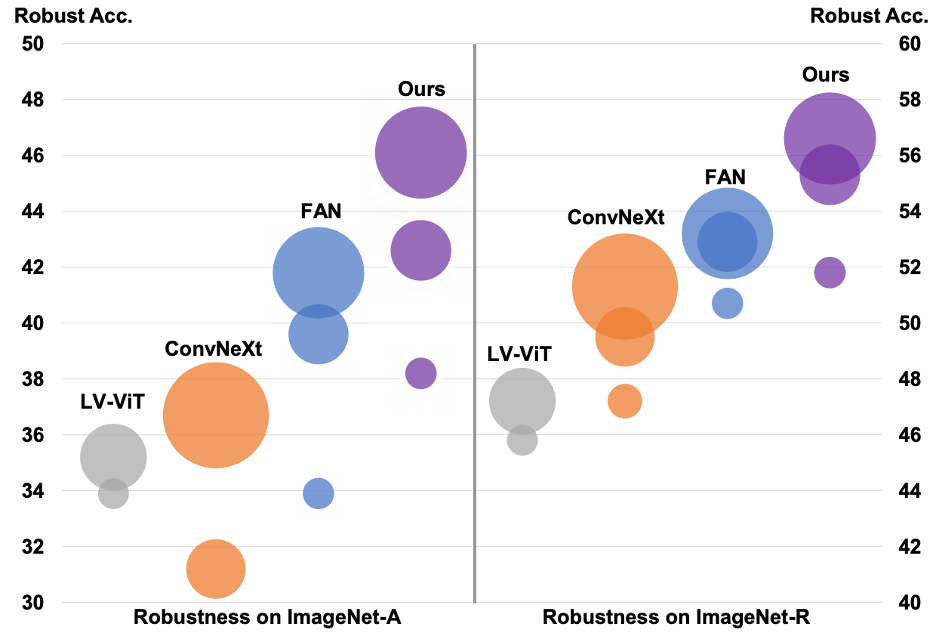
Recent studies indicate that Vision Transformers (ViTs) are robust against out-of-distribution scenarios. In particular, the Fully Attentional Network (FAN) - a family of ViT backbones, has achieved state-of-the-art robustness. In this paper, we revisit the FAN models and improve their pre-training with a self-emerging token labeling (STL) framework. Our method contains a two-stage training framework. Specifically, we first train a FAN token labeler (FAN-TL) to generate semantically meaningful patch token labels, followed by a FAN student model training stage that uses both the token labels and the original class label. With the proposed STL framework, our best model based on FAN-L-Hybrid (77.3M parameters) achieves 84.8% Top-1 accuracy and 42.1% mCE on ImageNet-1K and ImageNet-C, and sets a new state-of-the-art for ImageNet-A (46.1%) and ImageNet-R (56.6%) without using extra data, outperforming the original FAN counterpart by significant margins. The proposed framework also demonstrates significantly enhanced performance on downstream tasks such as semantic segmentation, with up to 1.7% improvement in robustness over the counterpart model. Code is available at https://github.com/NVlabs/STL.
PDF Abstract ICCV 2023 PDF ICCV 2023 AbstractCode

Tasks

Datasets
 ImageNet
ImageNet
 MS COCO
MS COCO
 Cityscapes
Cityscapes
 ImageNet-C
ImageNet-C
 ImageNet-R
ImageNet-R
 ImageNet-A
ImageNet-A

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Semantic Segmentation | Cityscapes val | FAN-L-Hybrid+STL | mIoU | 82.8 | # 27 | |
| Domain Generalization | ImageNet-A | FAN-L-Hybrid+STL | Top-1 accuracy % | 46.1 | # 22 | |
| Domain Generalization | ImageNet-C | FAN-L-Hybrid+STL | mean Corruption Error (mCE) | 42.1 | # 16 | |
| Top 1 Accuracy | 69.2 | # 3 | ||||
| Number of params | 77M | # 31 | ||||
| Domain Generalization | ImageNet-R | FAN-L-Hybrid+STL | Top-1 Error Rate | 43.4 | # 18 |
