Full-frequency dynamic convolution: a physical frequency-dependent convolution for sound event detection
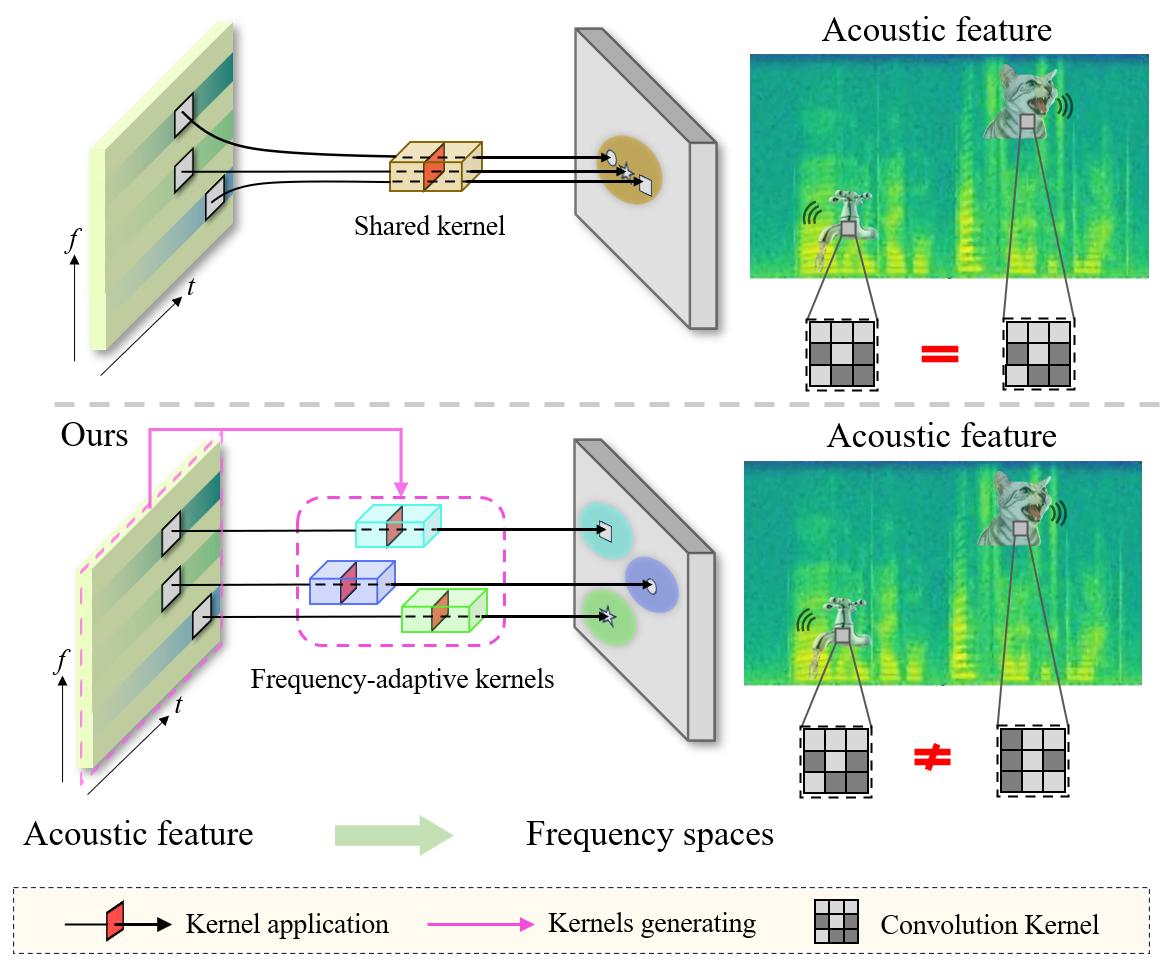
Recently, 2D convolution has been found unqualified in sound event detection (SED). It enforces translation equivariance on sound events along frequency axis, which is not a shift-invariant dimension. To address this issue, dynamic convolution is used to model the frequency dependency of sound events. In this paper, we proposed the first full-dynamic method named \emph{full-frequency dynamic convolution} (FFDConv). FFDConv generates frequency kernels for every frequency band, which is designed directly in the structure for frequency-dependent modeling. It physically furnished 2D convolution with the capability of frequency-dependent modeling. FFDConv outperforms not only the baseline by 6.6\% in DESED real validation dataset in terms of PSDS1, but outperforms the other full-dynamic methods. In addition, by visualizing features of sound events, we observed that FFDConv could effectively extract coherent features in specific frequency bands, consistent with the vocal continuity of sound events. This proves that FFDConv has great frequency-dependent perception ability.
PDF Abstract
 DESED
DESED
