From Sparse to Soft Mixtures of Experts
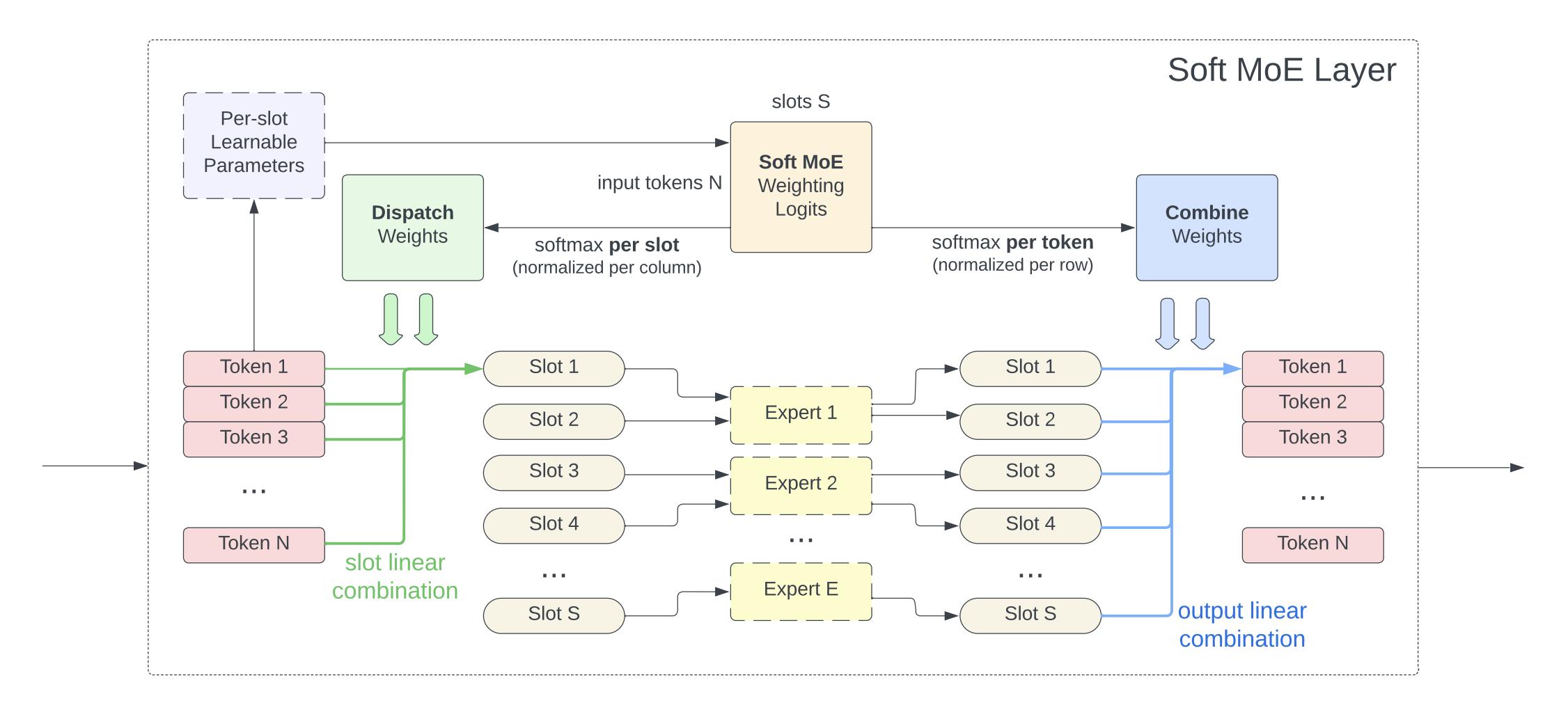
Sparse mixture of expert architectures (MoEs) scale model capacity without large increases in training or inference costs. Despite their success, MoEs suffer from a number of issues: training instability, token dropping, inability to scale the number of experts, or ineffective finetuning. In this work, we proposeSoft MoE, a fully-differentiable sparse Transformer that addresses these challenges, while maintaining the benefits of MoEs. Soft MoE performs an implicit soft assignment by passing different weighted combinations of all input tokens to each expert. As in other MoE works, experts in Soft MoE only process a subset of the (combined) tokens, enabling larger model capacity at lower inference cost. In the context of visual recognition, Soft MoE greatly outperforms standard Transformers (ViTs) and popular MoE variants (Tokens Choice and Experts Choice). For example, Soft MoE-Base/16 requires 10.5x lower inference cost (5.7x lower wall-clock time) than ViT-Huge/14 while matching its performance after similar training. Soft MoE also scales well: Soft MoE Huge/14 with 128 experts in 16 MoE layers has over 40x more parameters than ViT Huge/14, while inference time cost grows by only 2%, and it performs substantially better.
PDF Abstract

 ImageNet
ImageNet
