VeCLIP: Improving CLIP Training via Visual-enriched Captions
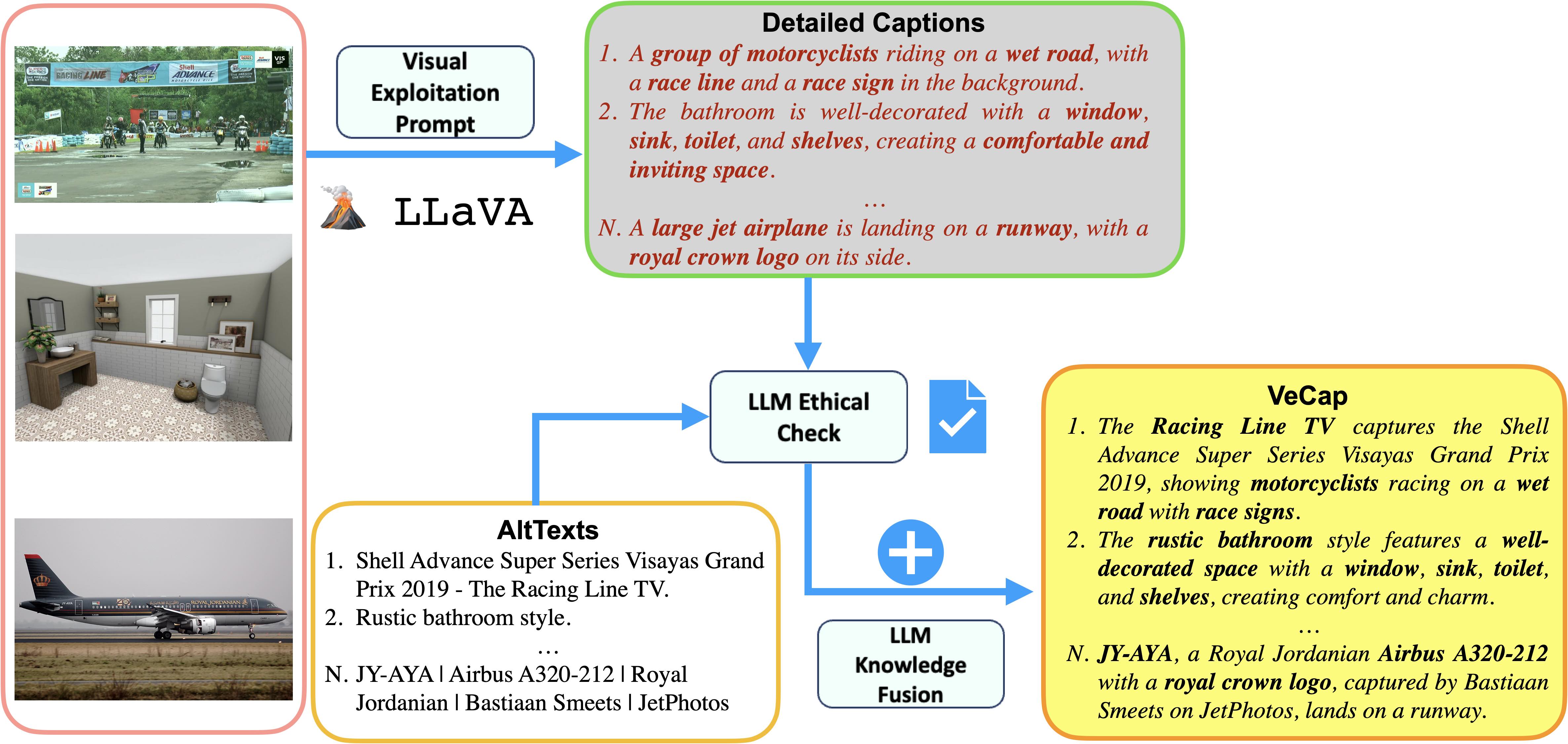
Large-scale web-crawled datasets are fundamental for the success of pre-training vision-language models, such as CLIP. However, the inherent noise and potential irrelevance of web-crawled AltTexts pose challenges in achieving precise image-text alignment. Existing methods utilizing large language models (LLMs) for caption rewriting have shown promise on small, curated datasets like CC3M and CC12M. This study introduces a scalable pipeline for noisy caption rewriting. Unlike recent LLM rewriting techniques, we emphasize the incorporation of visual concepts into captions, termed as Visual-enriched Captions (VeCap). To ensure data diversity, we propose a novel mixed training scheme that optimizes the utilization of AltTexts alongside newly generated VeCap. We showcase the adaptation of this method for training CLIP on large-scale web-crawled datasets, termed VeCLIP. Employing this cost-effective pipeline, we effortlessly scale our dataset up to 300 million samples named VeCap dataset. Our results show significant advantages in image-text alignment and overall model performance. For example, VeCLIP achieves up to +25.2% gain in COCO and Flickr30k retrieval tasks under the 12M setting. For data efficiency, VeCLIP achieves +3% gain while only using 14% of the data employed in the vanilla CLIP and 11% in ALIGN. We also note the VeCap data is complementary with other well curated datasets good for zero-shot classification tasks. When combining VeCap and DFN, our model can achieve strong performance on both of image-text retrieval and zero-shot classification tasks, e.g. 83.1% accuracy@1 on ImageNet zero-shot for a H/14 model. We release the pre-trained models at https://github.com/apple/ml-veclip.
PDF Abstract


 ImageNet
ImageNet
 MS COCO
MS COCO
 Oxford 102 Flower
Oxford 102 Flower
 Flickr30k
Flickr30k
 Caltech-101
Caltech-101
 CC12M
CC12M
