From PEFT to DEFT: Parameter Efficient Finetuning for Reducing Activation Density in Transformers
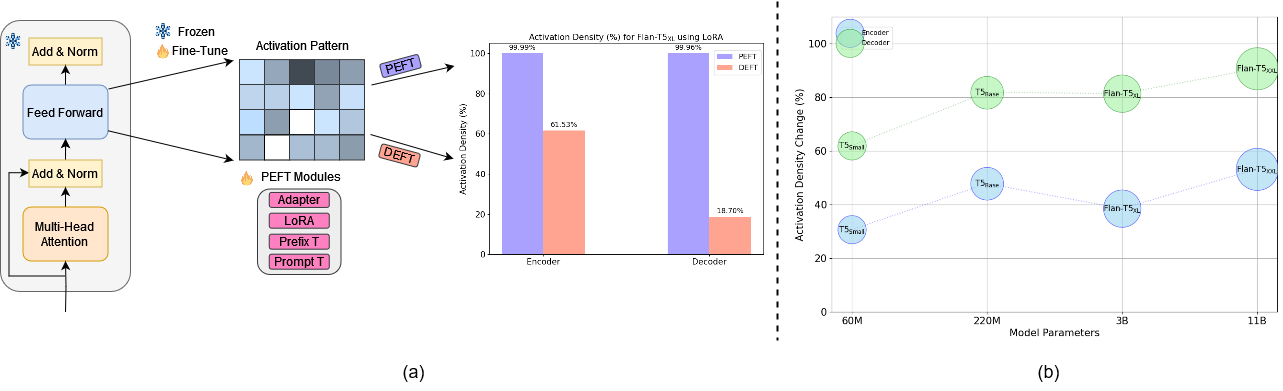
Pretrained Language Models (PLMs) have become the de facto starting point for fine-tuning on downstream tasks. However, as model sizes continue to increase, traditional fine-tuning of all parameters becomes challenging. To address this, parameter-efficient fine-tuning (PEFT) methods have gained popularity as a means to adapt PLMs effectively. In parallel, recent studies have revealed the presence of activation sparsity within the intermediate outputs of the multilayer perception (MLP) blocks in transformers. Low activation density enables efficient model inference on sparsity-aware hardware. Building upon this insight, in this work, we propose a novel density loss that encourages higher activation sparsity (equivalently, lower activation density) in the pre-trained models. We demonstrate the effectiveness of our approach by utilizing mainstream PEFT techniques including QLoRA, LoRA, Adapter, Prompt/Prefix Tuning to facilitate efficient model adaptation across diverse downstream tasks. Experiments show that our proposed method DEFT, Density-Efficient Fine-Tuning, can reduce the activation density consistently and up to $\boldsymbol{50.72\%}$ on RoBERTa$_\mathrm{Large}$, and $\boldsymbol {53.19\%}$ (encoder density) and $\boldsymbol{90.60\%}$ (decoder density) on Flan-T5$_\mathrm{XXL}$ ($\boldsymbol{11B}$) compared to PEFT using GLUE and QA (SQuAD) benchmarks respectively while maintaining competitive performance on downstream tasks. We also showcase that DEFT works complementary with quantized and pruned models
PDF Abstract
 GLUE
GLUE
 SQuAD
SQuAD
 QNLI
QNLI
