From Hero to Zéroe: A Benchmark of Low-Level Adversarial Attacks
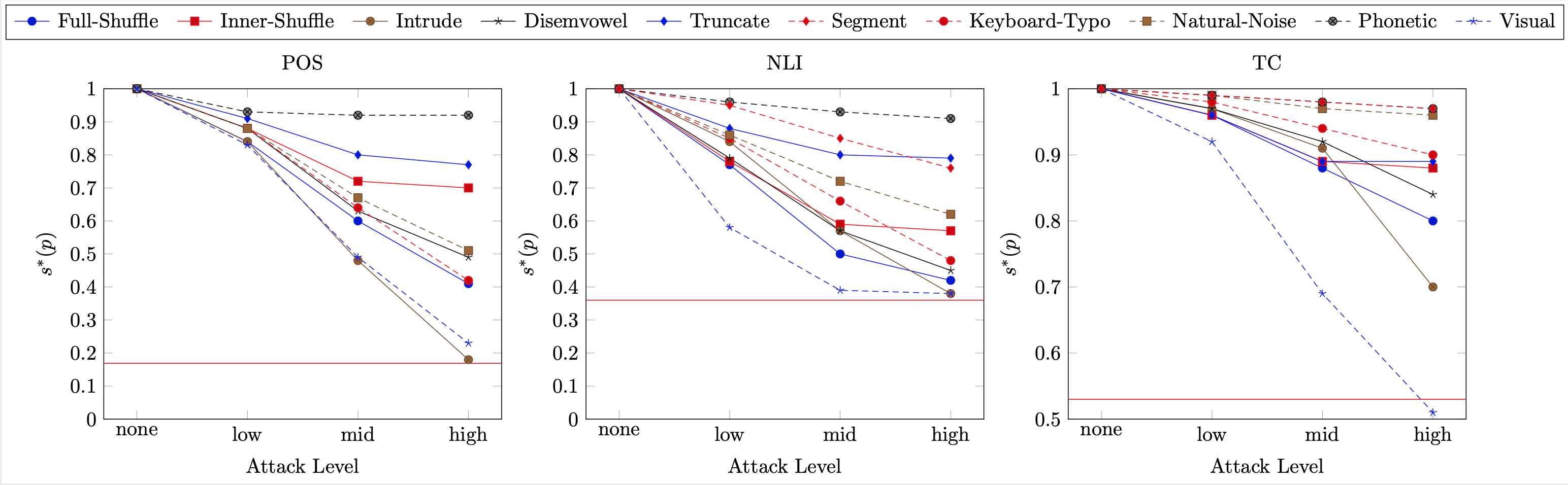
Adversarial attacks are label-preserving modifications to inputs of machine learning classifiers designed to fool machines but not humans. Natural Language Processing (NLP) has mostly focused on high-level attack scenarios such as paraphrasing input texts. We argue that these are less realistic in typical application scenarios such as in social media, and instead focus on low-level attacks on the character-level. Guided by human cognitive abilities and human robustness, we propose the first large-scale catalogue and benchmark of low-level adversarial attacks, which we dub Z\'eroe, encompassing nine different attack modes including visual and phonetic adversaries. We show that RoBERTa, NLP's current workhorse, fails on our attacks. Our dataset provides a benchmark for testing robustness of future more human-like NLP models.
PDF Abstract


