Foundation Model for Endoscopy Video Analysis via Large-scale Self-supervised Pre-train
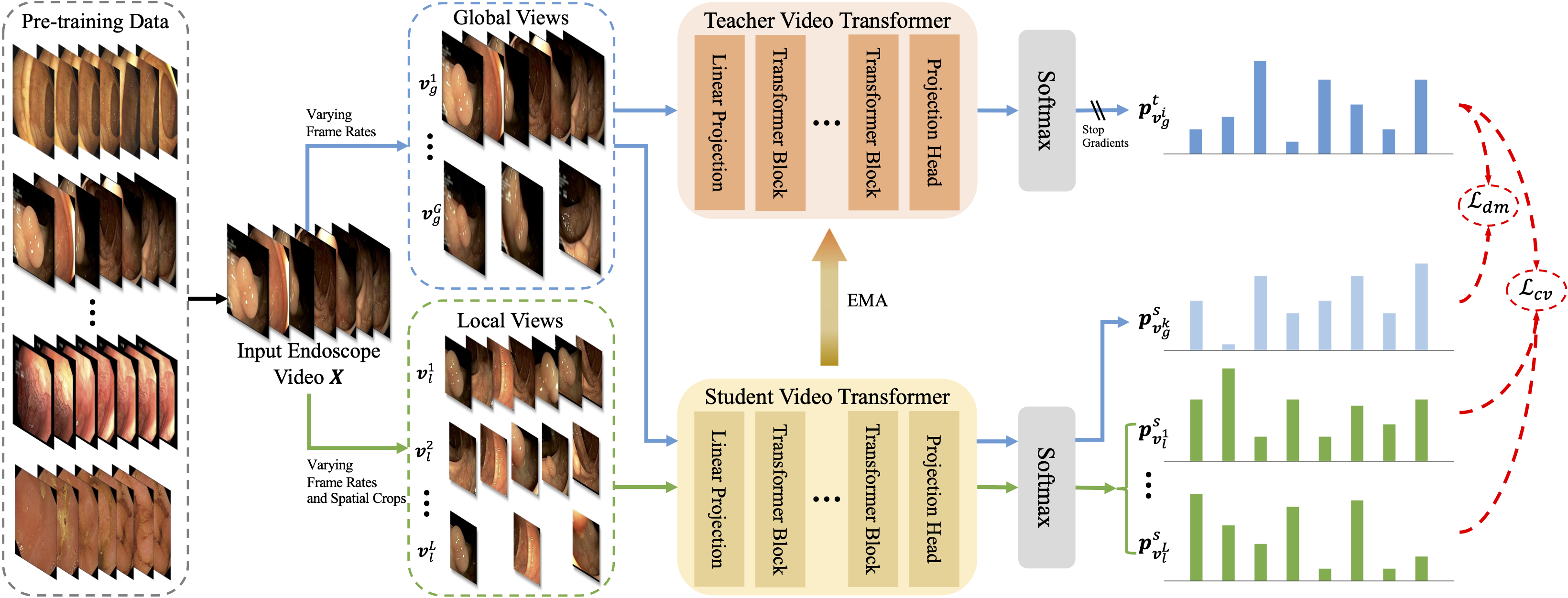
Foundation models have exhibited remarkable success in various applications, such as disease diagnosis and text report generation. To date, a foundation model for endoscopic video analysis is still lacking. In this paper, we propose Endo-FM, a foundation model specifically developed using massive endoscopic video data. First, we build a video transformer, which captures both local and global long-range dependencies across spatial and temporal dimensions. Second, we pre-train our transformer model using global and local views via a self-supervised manner, aiming to make it robust to spatial-temporal variations and discriminative across different scenes. To develop the foundation model, we construct a large-scale endoscopy video dataset by combining 9 publicly available datasets and a privately collected dataset from Baoshan Branch of Renji Hospital in Shanghai, China. Our dataset overall consists of over 33K video clips with up to 5 million frames, encompassing various protocols, target organs, and disease types. Our pre-trained Endo-FM can be easily adopted for a given downstream task via fine-tuning by serving as the backbone. With experiments on 3 different types of downstream tasks, including classification, segmentation, and detection, our Endo-FM surpasses the current state-of-the-art (SOTA) self-supervised pre-training and adapter-based transfer learning methods by a significant margin, such as VCL (3.1% F1, 4.8% Dice, and 5.5% F1 for classification, segmentation, and detection) and ST-Adapter (5.9% F1, 9.6% Dice, and 9.9% F1 for classification, segmentation, and detection). Code, datasets, and models are released at https://github.com/med-air/Endo-FM.
PDF Abstract


 KUMC
KUMC
