Flexible Performant GEMM Kernels on GPUs
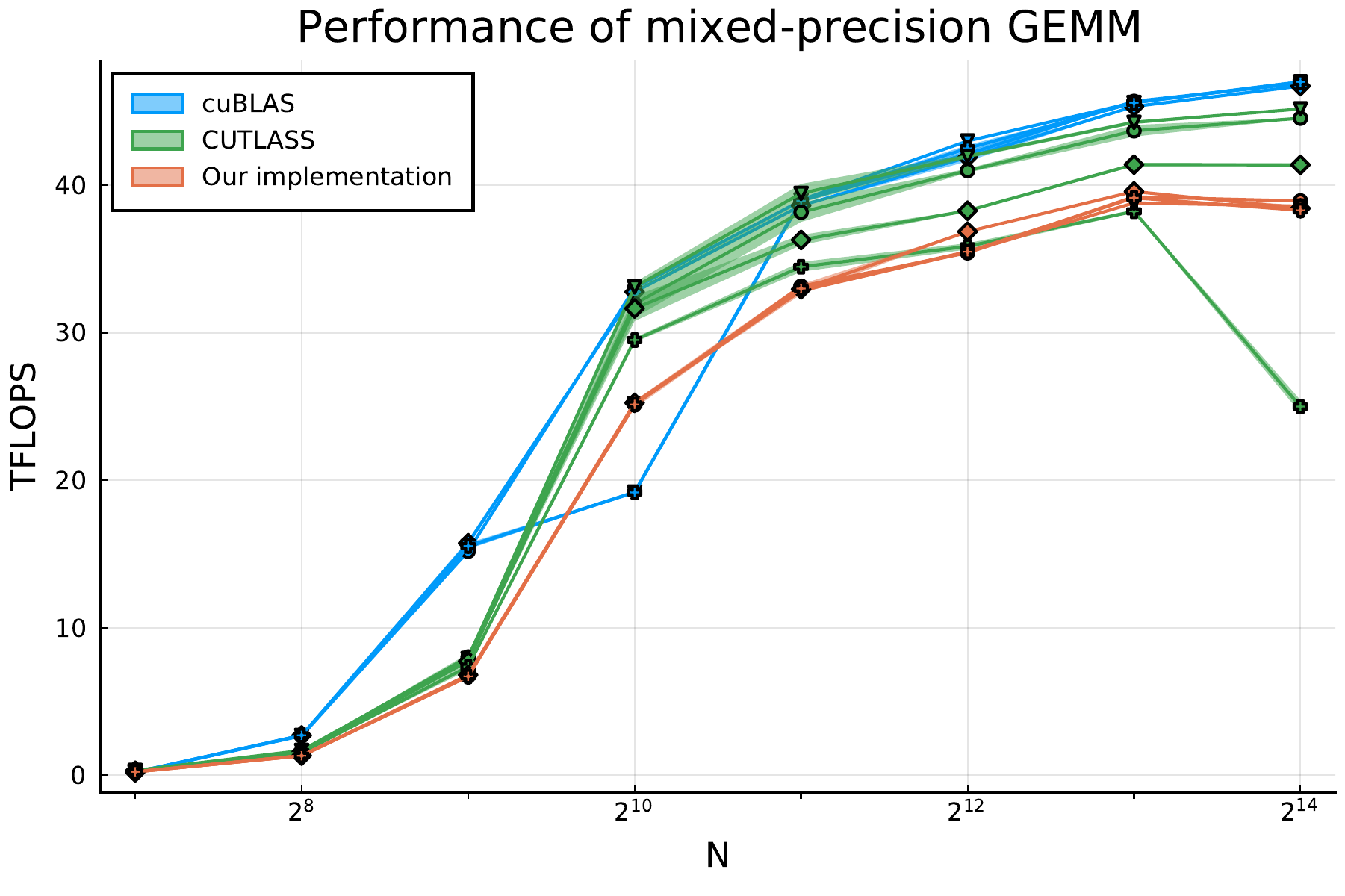
General Matrix Multiplication or GEMM kernels take centre place in high performance computing and machine learning. Recent NVIDIA GPUs include GEMM accelerators, such as NVIDIA's Tensor Cores. Their exploitation is hampered by the two-language problem: it requires either low-level programming which implies low programmer productivity or using libraries that only offer a limited set of components. Because rephrasing algorithms in terms of established components often introduces overhead, the libraries' lack of flexibility limits the freedom to explore new algorithms. Researchers using GEMMs can hence not enjoy programming productivity, high performance, and research flexibility at once. In this paper we solve this problem. We present three sets of abstractions and interfaces to program GEMMs within the scientific Julia programming language. The interfaces and abstractions are co-designed for researchers' needs and Julia's features to achieve sufficient separation of concerns and flexibility to easily extend basic GEMMs in many different ways without paying a performance price. Comparing our GEMMs to state-of-the-art libraries cuBLAS and CUTLASS, we demonstrate that our performance is in the same ballpark of the libraries, and in some cases even exceeds it, without having to write a single line of code in CUDA C++ or assembly, and without facing flexibility limitations.
PDF Abstract