FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets
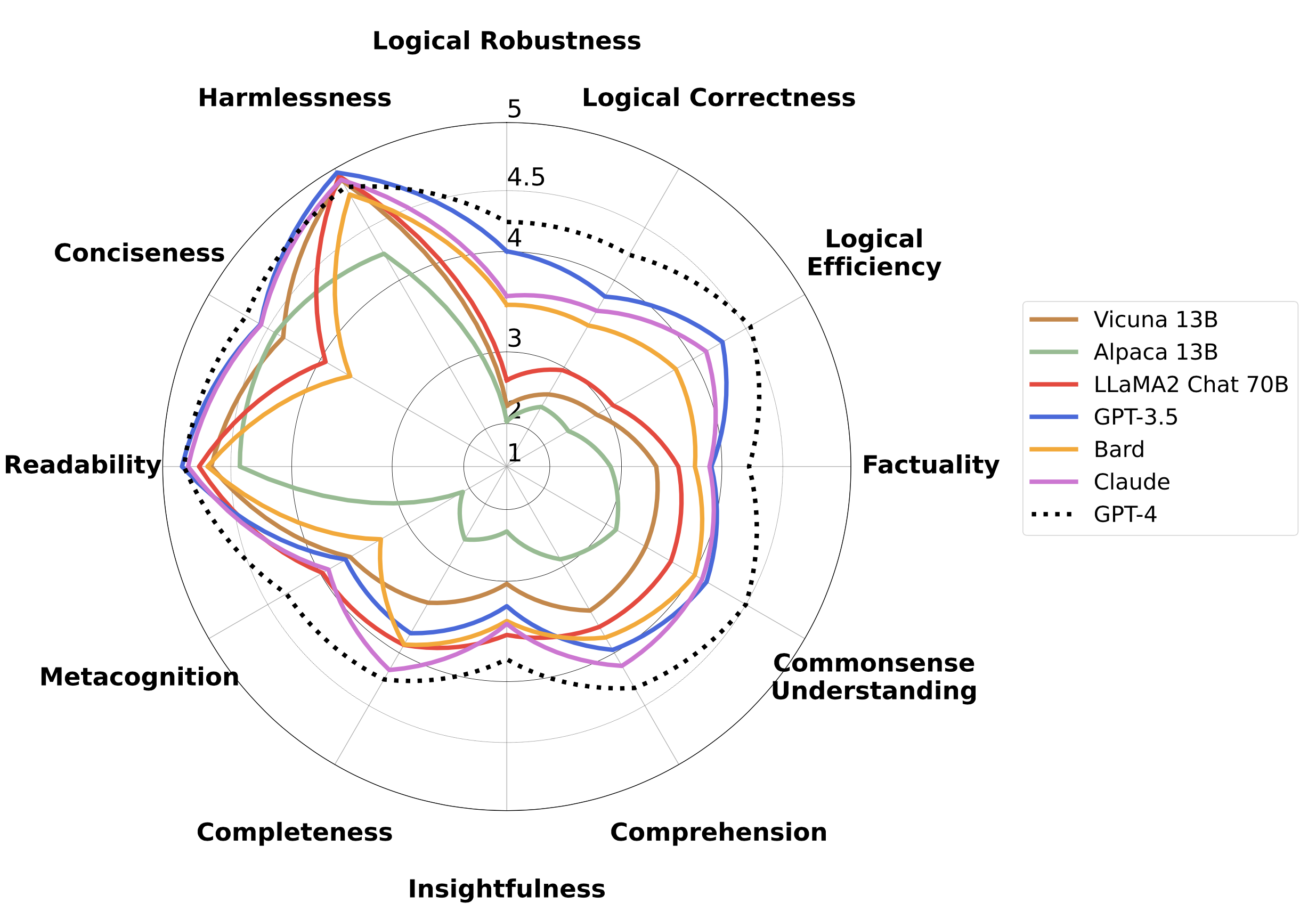
Evaluation of Large Language Models (LLMs) is challenging because instruction-following necessitates alignment with human values and the required set of skills varies depending on the instruction. However, previous studies have mainly focused on coarse-grained evaluation (i.e. overall preference-based evaluation), which limits interpretability since it does not consider the nature of user instructions that require instance-wise skill composition. In this paper, we introduce FLASK (Fine-grained Language Model Evaluation based on Alignment Skill Sets), a fine-grained evaluation protocol for both human-based and model-based evaluation which decomposes coarse-level scoring to a skill set-level scoring for each instruction. We experimentally observe that the fine-graininess of evaluation is crucial for attaining a holistic view of model performance and increasing the reliability of the evaluation. Using FLASK, we compare multiple open-source and proprietary LLMs and observe a high correlation between model-based and human-based evaluations. We publicly release the evaluation data and code implementation at https://github.com/kaistAI/FLASK.
PDF Abstract

 GSM8K
GSM8K
