FishDreamer: Towards Fisheye Semantic Completion via Unified Image Outpainting and Segmentation
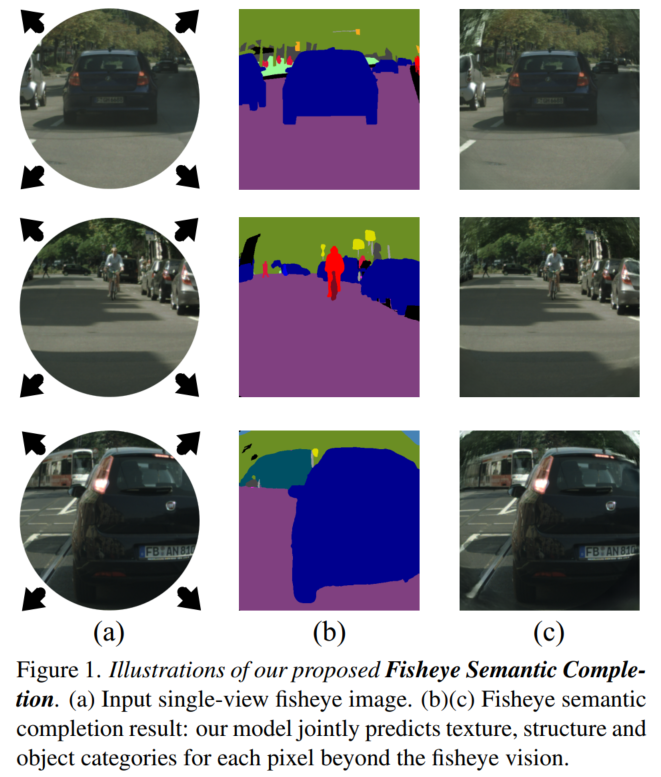
This paper raises the new task of Fisheye Semantic Completion (FSC), where dense texture, structure, and semantics of a fisheye image are inferred even beyond the sensor field-of-view (FoV). Fisheye cameras have larger FoV than ordinary pinhole cameras, yet its unique special imaging model naturally leads to a blind area at the edge of the image plane. This is suboptimal for safety-critical applications since important perception tasks, such as semantic segmentation, become very challenging within the blind zone. Previous works considered the out-FoV outpainting and in-FoV segmentation separately. However, we observe that these two tasks are actually closely coupled. To jointly estimate the tightly intertwined complete fisheye image and scene semantics, we introduce the new FishDreamer which relies on successful ViTs enhanced with a novel Polar-aware Cross Attention module (PCA) to leverage dense context and guide semantically-consistent content generation while considering different polar distributions. In addition to the contribution of the novel task and architecture, we also derive Cityscapes-BF and KITTI360-BF datasets to facilitate training and evaluation of this new track. Our experiments demonstrate that the proposed FishDreamer outperforms methods solving each task in isolation and surpasses alternative approaches on the Fisheye Semantic Completion. Code and datasets are publicly available at https://github.com/MasterHow/FishDreamer.
PDF Abstract


 Cityscapes
Cityscapes
 KITTI-360
KITTI-360
