Finding Foundation Models for Time Series Classification with a PreText Task
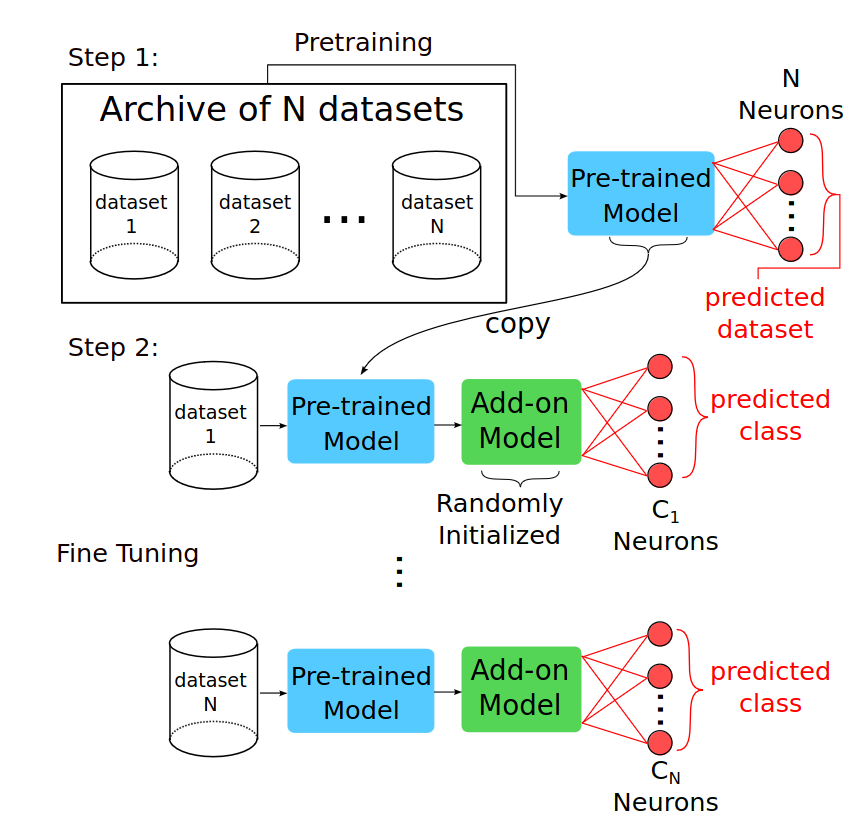
Over the past decade, Time Series Classification (TSC) has gained an increasing attention. While various methods were explored, deep learning - particularly through Convolutional Neural Networks (CNNs)-stands out as an effective approach. However, due to the limited availability of training data, defining a foundation model for TSC that overcomes the overfitting problem is still a challenging task. The UCR archive, encompassing a wide spectrum of datasets ranging from motion recognition to ECG-based heart disease detection, serves as a prime example for exploring this issue in diverse TSC scenarios. In this paper, we address the overfitting challenge by introducing pre-trained domain foundation models. A key aspect of our methodology is a novel pretext task that spans multiple datasets. This task is designed to identify the originating dataset of each time series sample, with the goal of creating flexible convolution filters that can be applied across different datasets. The research process consists of two phases: a pre-training phase where the model acquires general features through the pretext task, and a subsequent fine-tuning phase for specific dataset classifications. Our extensive experiments on the UCR archive demonstrate that this pre-training strategy significantly outperforms the conventional training approach without pre-training. This strategy effectively reduces overfitting in small datasets and provides an efficient route for adapting these models to new datasets, thus advancing the capabilities of deep learning in TSC.
PDF Abstract

