FastFormers: Highly Efficient Transformer Models for Natural Language Understanding
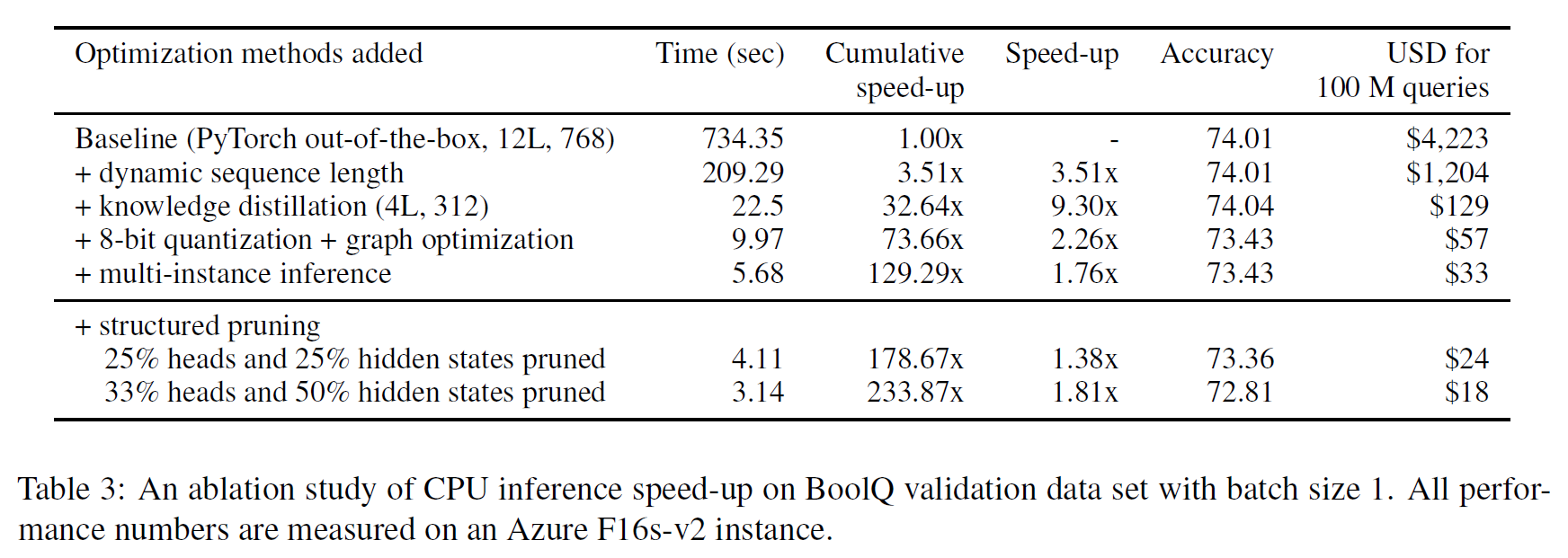
Transformer-based models are the state-of-the-art for Natural Language Understanding (NLU) applications. Models are getting bigger and better on various tasks. However, Transformer models remain computationally challenging since they are not efficient at inference-time compared to traditional approaches. In this paper, we present FastFormers, a set of recipes to achieve efficient inference-time performance for Transformer-based models on various NLU tasks. We show how carefully utilizing knowledge distillation, structured pruning and numerical optimization can lead to drastic improvements on inference efficiency. We provide effective recipes that can guide practitioners to choose the best settings for various NLU tasks and pretrained models. Applying the proposed recipes to the SuperGLUE benchmark, we achieve from 9.8x up to 233.9x speed-up compared to out-of-the-box models on CPU. On GPU, we also achieve up to 12.4x speed-up with the presented methods. We show that FastFormers can drastically reduce cost of serving 100 million requests from 4,223 USD to just 18 USD on an Azure F16s_v2 instance. This translates to a sustainable runtime by reducing energy consumption 6.9x - 125.8x according to the metrics used in the SustaiNLP 2020 shared task.
PDF Abstract EMNLP (sustainlp) 2020 PDF EMNLP (sustainlp) 2020 Abstract

 SuperGLUE
SuperGLUE
