Facilitating Pornographic Text Detection for Open-Domain Dialogue Systems via Knowledge Distillation of Large Language Models
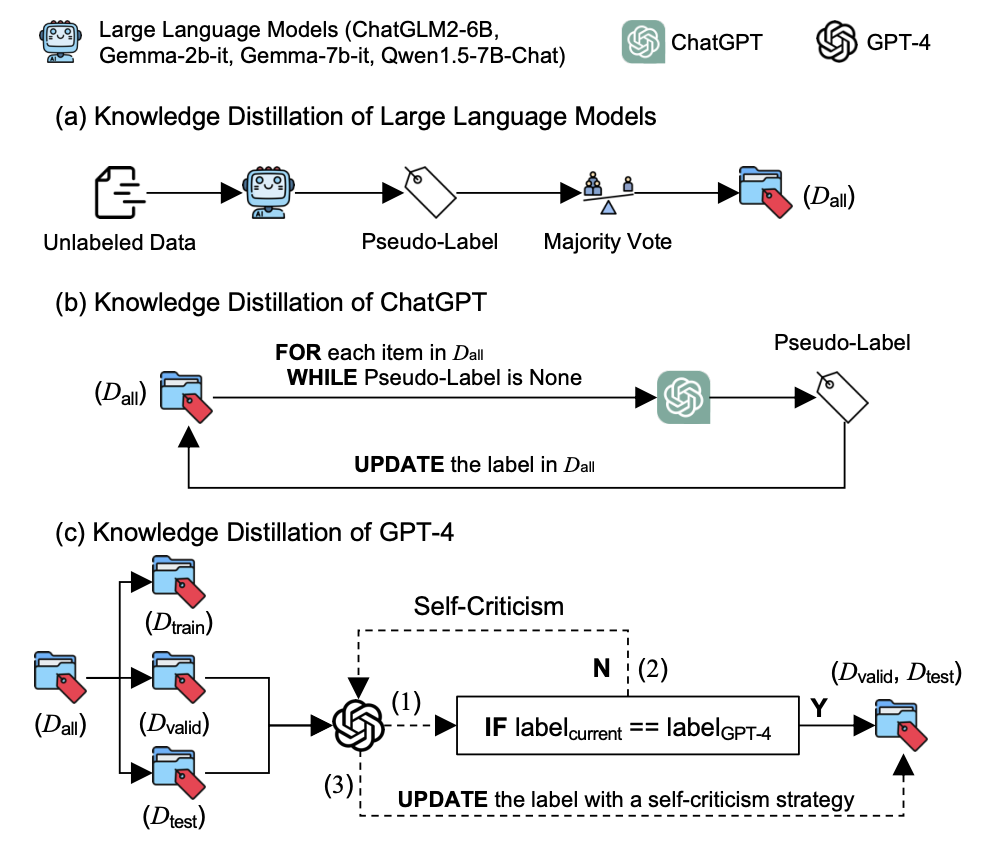
Pornographic content occurring in human-machine interaction dialogues can cause severe side effects for users in open-domain dialogue systems. However, research on detecting pornographic language within human-machine interaction dialogues is an important subject that is rarely studied. To advance in this direction, we introduce CensorChat, a dialogue monitoring dataset aimed at detecting whether the dialogue session contains pornographic content. To this end, we collect real-life human-machine interaction dialogues in the wild and break them down into single utterances and single-turn dialogues, with the last utterance spoken by the chatbot. We propose utilizing knowledge distillation of large language models to annotate the dataset. Specifically, first, the raw dataset is annotated by four open-source large language models, with the majority vote determining the label. Second, we use ChatGPT to update the empty label from the first step. Third, to ensure the quality of the validation and test sets, we utilize GPT-4 for label calibration. If the current label does not match the one generated by GPT-4, we employ a self-criticism strategy to verify its correctness. Finally, to facilitate the detection of pornographic text, we develop a series of text classifiers using a pseudo-labeled dataset. Detailed data analysis demonstrates that leveraging knowledge distillation techniques with large language models provides a practical and cost-efficient method for developing pornographic text detectors.
PDF Abstract


