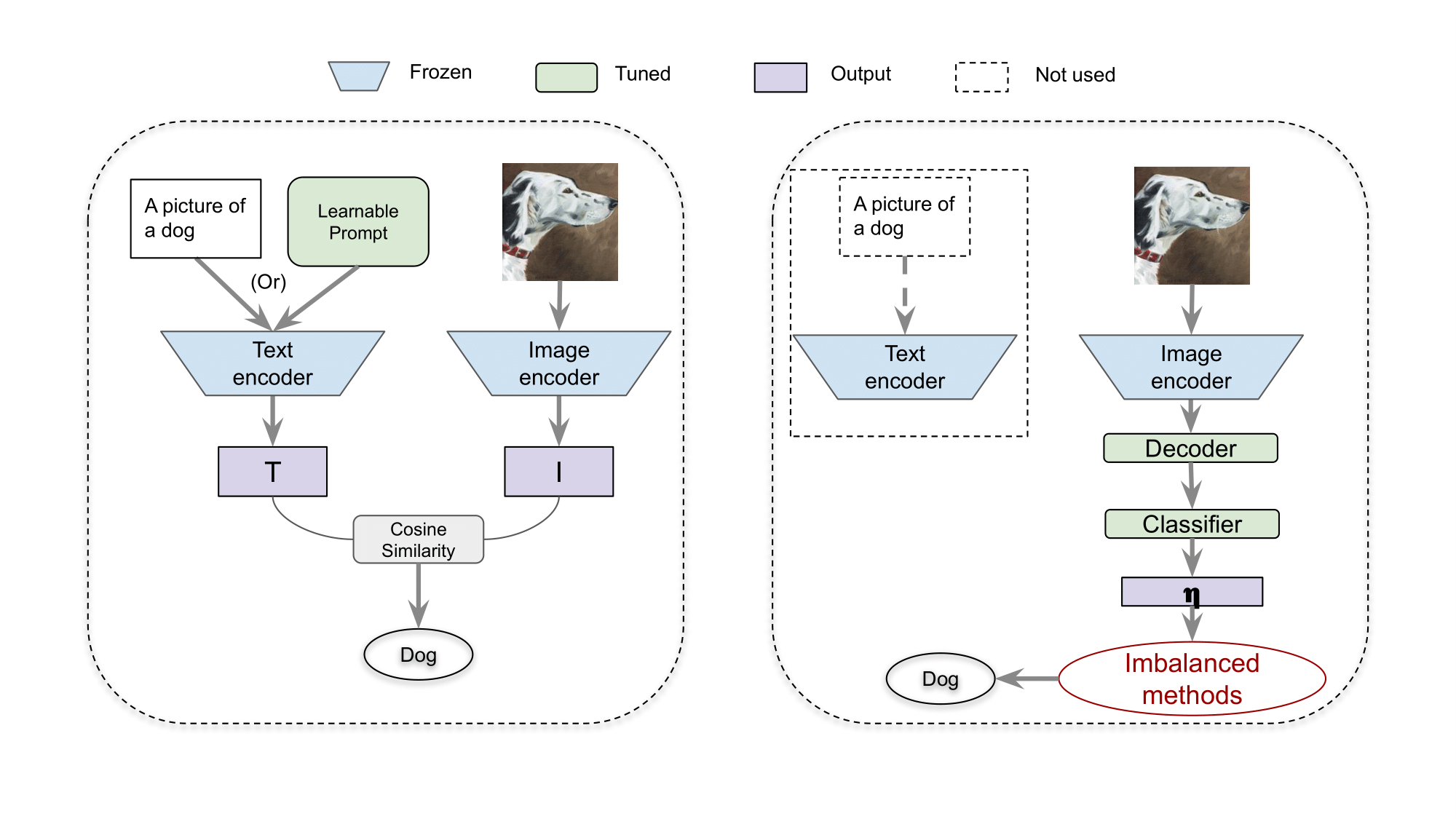
Exploring Vision-Language Models for Imbalanced Learning
Vision-Language models (VLMs) that use contrastive language-image pre-training have shown promising zero-shot classification performance. However, their performance on imbalanced dataset is relatively poor, where the distribution of classes in the training dataset is skewed, leading to poor performance in predicting minority classes. For instance, CLIP achieved only 5% accuracy on the iNaturalist18 dataset. We propose to add a lightweight decoder to VLMs to avoid OOM (out of memory) problem caused by large number of classes and capture nuanced features for tail classes. Then, we explore improvements of VLMs using prompt tuning, fine-tuning, and incorporating imbalanced algorithms such as Focal Loss, Balanced SoftMax and Distribution Alignment. Experiments demonstrate that the performance of VLMs can be further boosted when used with decoder and imbalanced methods. Specifically, our improved VLMs significantly outperforms zero-shot classification by an average accuracy of 6.58%, 69.82%, and 6.17%, on ImageNet-LT, iNaturalist18, and Places-LT, respectively. We further analyze the influence of pre-training data size, backbones, and training cost. Our study highlights the significance of imbalanced learning algorithms in face of VLMs pre-trained by huge data. We release our code at https://github.com/Imbalance-VLM/Imbalance-VLM.
PDF Abstract

 Places
Places
 iNaturalist
iNaturalist
