Exploring intermediate representation for monocular vehicle pose estimation
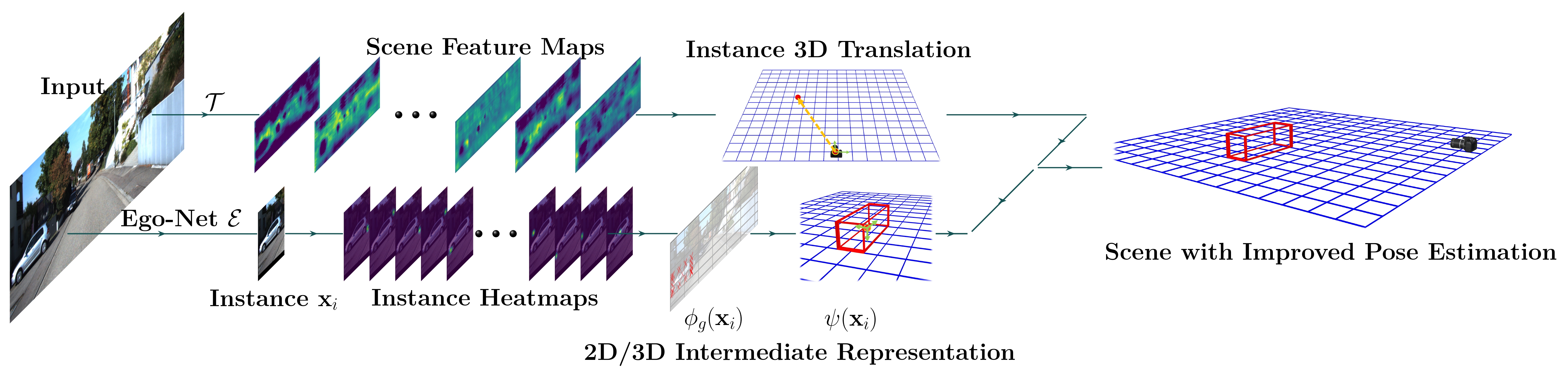
We present a new learning-based framework to recover vehicle pose in SO(3) from a single RGB image. In contrast to previous works that map from local appearance to observation angles, we explore a progressive approach by extracting meaningful Intermediate Geometrical Representations (IGRs) to estimate egocentric vehicle orientation. This approach features a deep model that transforms perceived intensities to IGRs, which are mapped to a 3D representation encoding object orientation in the camera coordinate system. Core problems are what IGRs to use and how to learn them more effectively. We answer the former question by designing IGRs based on an interpolated cuboid that derives from primitive 3D annotation readily. The latter question motivates us to incorporate geometry knowledge with a new loss function based on a projective invariant. This loss function allows unlabeled data to be used in the training stage to improve representation learning. Without additional labels, our system outperforms previous monocular RGB-based methods for joint vehicle detection and pose estimation on the KITTI benchmark, achieving performance even comparable to stereo methods. Code and pre-trained models are available at this https URL.
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract




 KITTI
KITTI

