Explainable Automated Coding of Clinical Notes using Hierarchical Label-wise Attention Networks and Label Embedding Initialisation
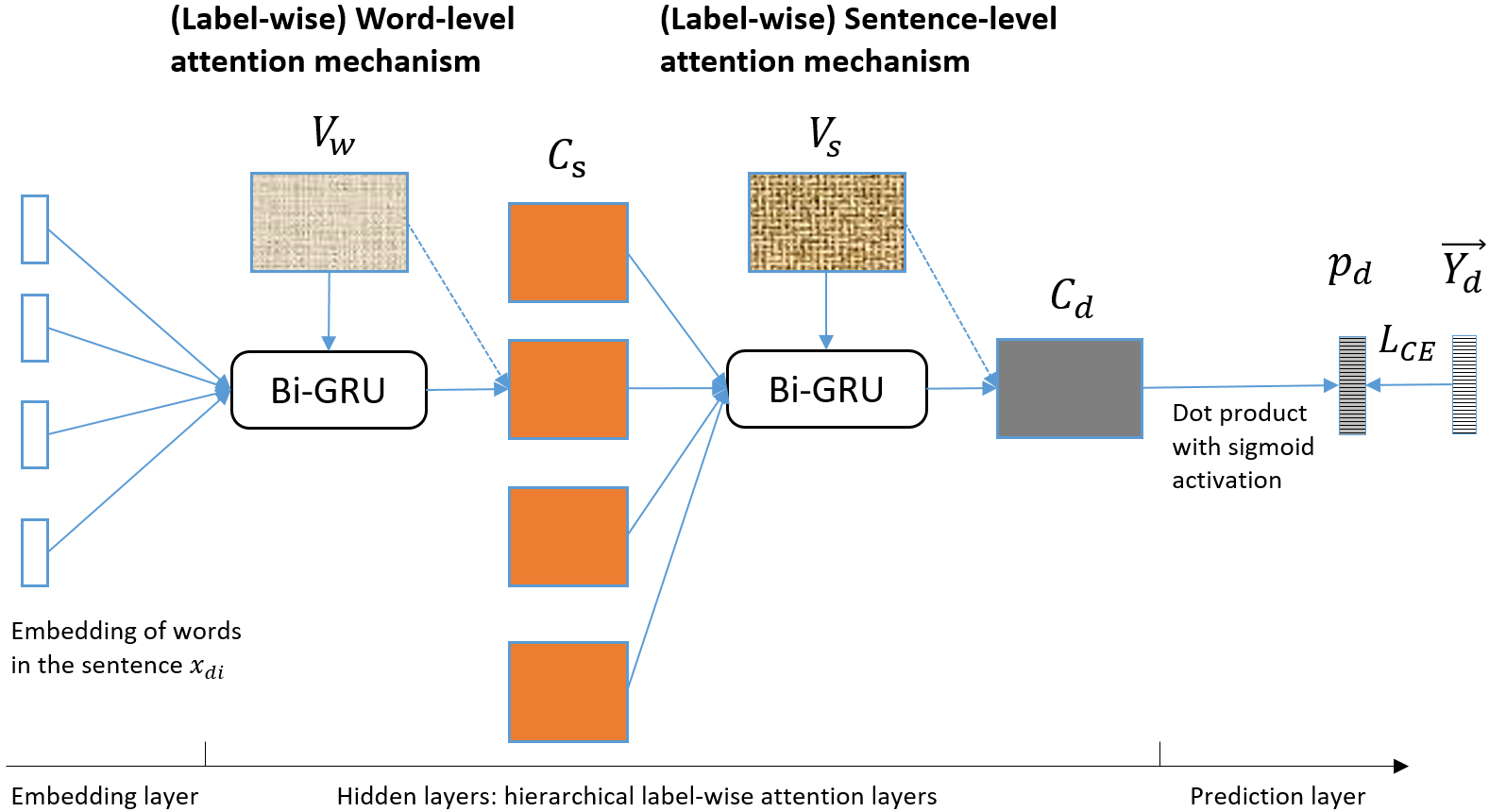
Diagnostic or procedural coding of clinical notes aims to derive a coded summary of disease-related information about patients. Such coding is usually done manually in hospitals but could potentially be automated to improve the efficiency and accuracy of medical coding. Recent studies on deep learning for automated medical coding achieved promising performances. However, the explainability of these models is usually poor, preventing them to be used confidently in supporting clinical practice. Another limitation is that these models mostly assume independence among labels, ignoring the complex correlation among medical codes which can potentially be exploited to improve the performance. We propose a Hierarchical Label-wise Attention Network (HLAN), which aimed to interpret the model by quantifying importance (as attention weights) of words and sentences related to each of the labels. Secondly, we propose to enhance the major deep learning models with a label embedding (LE) initialisation approach, which learns a dense, continuous vector representation and then injects the representation into the final layers and the label-wise attention layers in the models. We evaluated the methods using three settings on the MIMIC-III discharge summaries: full codes, top-50 codes, and the UK NHS COVID-19 shielding codes. Experiments were conducted to compare HLAN and LE initialisation to the state-of-the-art neural network based methods. HLAN achieved the best Micro-level AUC and $F_1$ on the top-50 code prediction and comparable results on the NHS COVID-19 shielding code prediction to other models. By highlighting the most salient words and sentences for each label, HLAN showed more meaningful and comprehensive model interpretation compared to its downgraded baselines and the CNN-based models. LE initialisation consistently boosted most deep learning models for automated medical coding.
PDF Abstract

 MIMIC-III
MIMIC-III

