Equivariant and Invariant Grounding for Video Question Answering
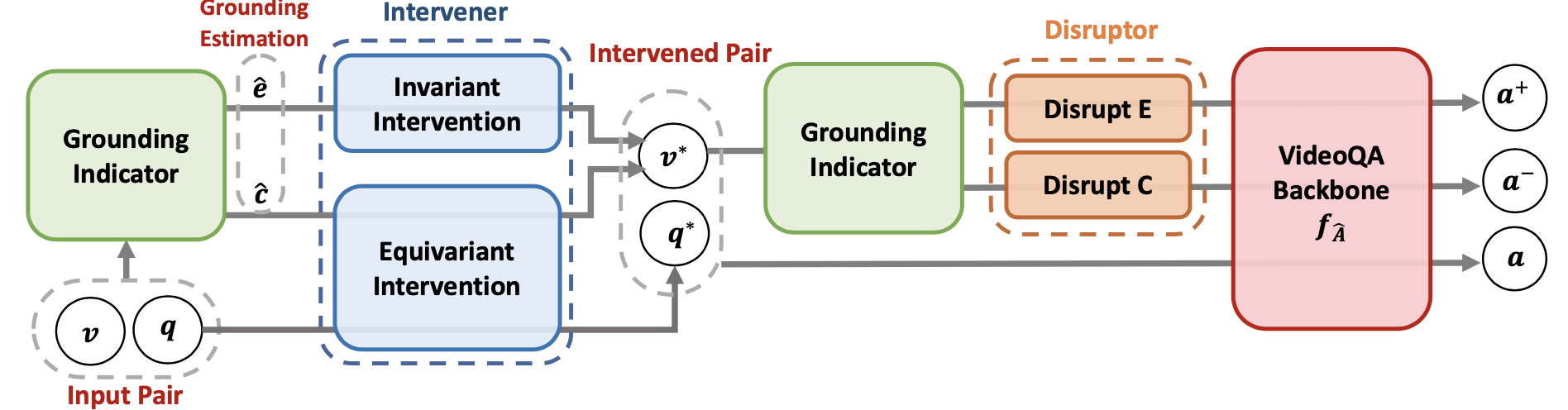
Video Question Answering (VideoQA) is the task of answering the natural language questions about a video. Producing an answer requires understanding the interplay across visual scenes in video and linguistic semantics in question. However, most leading VideoQA models work as black boxes, which make the visual-linguistic alignment behind the answering process obscure. Such black-box nature calls for visual explainability that reveals ``What part of the video should the model look at to answer the question?''. Only a few works present the visual explanations in a post-hoc fashion, which emulates the target model's answering process via an additional method. Nonetheless, the emulation struggles to faithfully exhibit the visual-linguistic alignment during answering. Instead of post-hoc explainability, we focus on intrinsic interpretability to make the answering process transparent. At its core is grounding the question-critical cues as the causal scene to yield answers, while rolling out the question-irrelevant information as the environment scene. Taking a causal look at VideoQA, we devise a self-interpretable framework, Equivariant and Invariant Grounding for Interpretable VideoQA (EIGV). Specifically, the equivariant grounding encourages the answering to be sensitive to the semantic changes in the causal scene and question; in contrast, the invariant grounding enforces the answering to be insensitive to the changes in the environment scene. By imposing them on the answering process, EIGV is able to distinguish the causal scene from the environment information, and explicitly present the visual-linguistic alignment. Extensive experiments on three benchmark datasets justify the superiority of EIGV in terms of accuracy and visual interpretability over the leading baselines.
PDF Abstract


 NExT-QA
NExT-QA
