End-to-end Autonomous Driving Perception with Sequential Latent Representation Learning
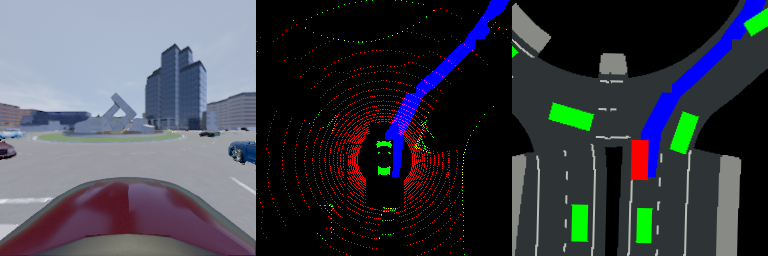
Current autonomous driving systems are composed of a perception system and a decision system. Both of them are divided into multiple subsystems built up with lots of human heuristics. An end-to-end approach might clean up the system and avoid huge efforts of human engineering, as well as obtain better performance with increasing data and computation resources. Compared to the decision system, the perception system is more suitable to be designed in an end-to-end framework, since it does not require online driving exploration. In this paper, we propose a novel end-to-end approach for autonomous driving perception. A latent space is introduced to capture all relevant features useful for perception, which is learned through sequential latent representation learning. The learned end-to-end perception model is able to solve the detection, tracking, localization and mapping problems altogether with only minimum human engineering efforts and without storing any maps online. The proposed method is evaluated in a realistic urban driving simulator, with both camera image and lidar point cloud as sensor inputs. The codes and videos of this work are available at our github repo and project website.
PDF Abstract


 CARLA
CARLA
