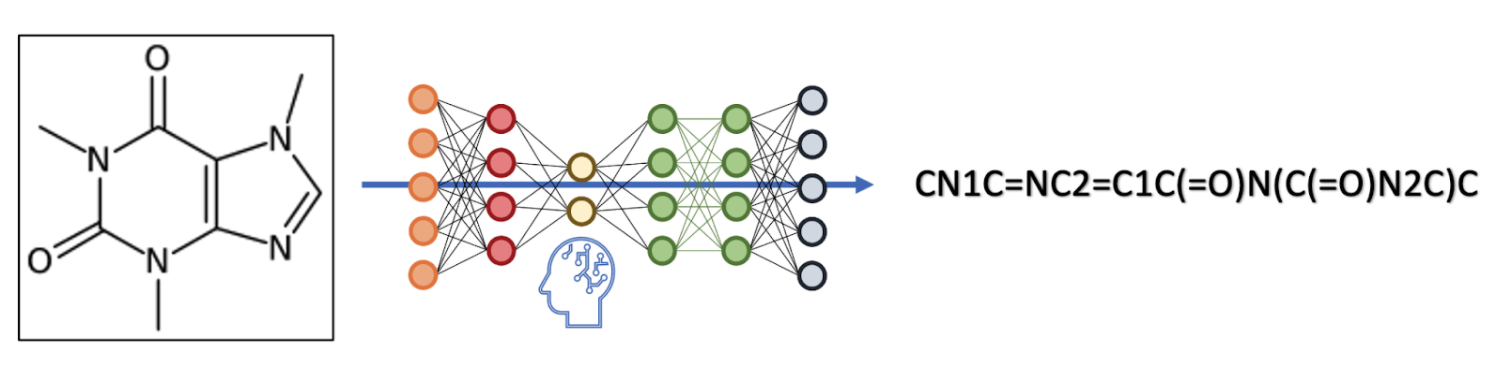
End-to-End Attention-based Image Captioning
In this paper, we address the problem of image captioning specifically for molecular translation where the result would be a predicted chemical notation in InChI format for a given molecular structure. Current approaches mainly follow rule-based or CNN+RNN based methodology. However, they seem to underperform on noisy images and images with small number of distinguishable features. To overcome this, we propose an end-to-end transformer model. When compared to attention-based techniques, our proposed model outperforms on molecular datasets.
PDF Abstract


Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
