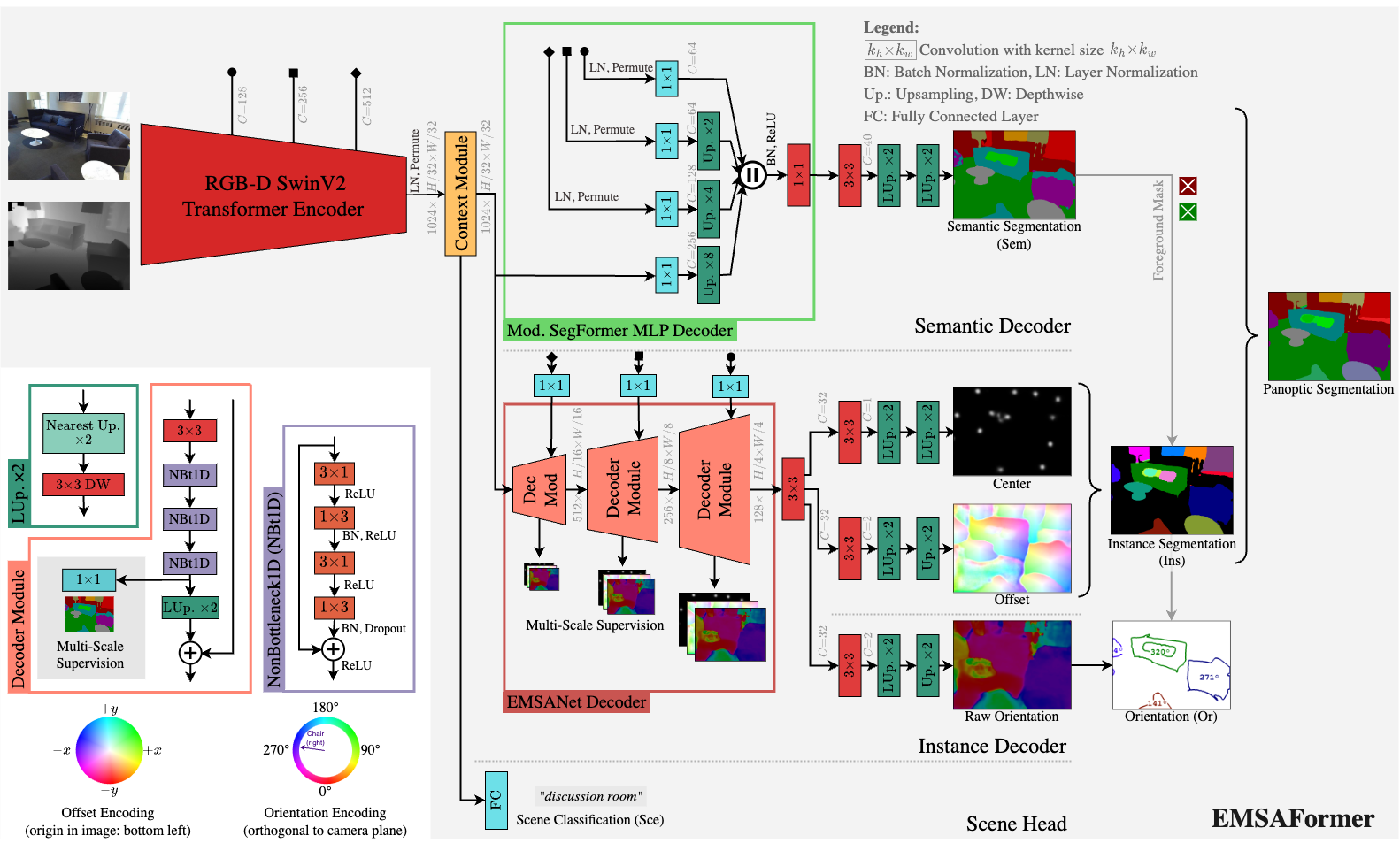
Efficient Multi-Task Scene Analysis with RGB-D Transformers
Scene analysis is essential for enabling autonomous systems, such as mobile robots, to operate in real-world environments. However, obtaining a comprehensive understanding of the scene requires solving multiple tasks, such as panoptic segmentation, instance orientation estimation, and scene classification. Solving these tasks given limited computing and battery capabilities on mobile platforms is challenging. To address this challenge, we introduce an efficient multi-task scene analysis approach, called EMSAFormer, that uses an RGB-D Transformer-based encoder to simultaneously perform the aforementioned tasks. Our approach builds upon the previously published EMSANet. However, we show that the dual CNN-based encoder of EMSANet can be replaced with a single Transformer-based encoder. To achieve this, we investigate how information from both RGB and depth data can be effectively incorporated in a single encoder. To accelerate inference on robotic hardware, we provide a custom NVIDIA TensorRT extension enabling highly optimization for our EMSAFormer approach. Through extensive experiments on the commonly used indoor datasets NYUv2, SUNRGB-D, and ScanNet, we show that our approach achieves state-of-the-art performance while still enabling inference with up to 39.1 FPS on an NVIDIA Jetson AGX Orin 32 GB.
PDF Abstract



 ScanNet
ScanNet
 NYUv2
NYUv2
 SUN RGB-D
SUN RGB-D

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Semantic Segmentation | NYU Depth v2 | EMSAFormer (SwinV2-T-128-Multi-Aug) | Mean IoU | 51.26% | # 40 | ||
| Semantic Segmentation | ScanNetV2 | EMSAFormer | Mean IoU | 56.4% | # 5 | ||
| Semantic Segmentation | SUN-RGBD | EMSANet (2x ResNet-34 NBt1D, PanopticNDT version, finetuned) | Mean IoU | 48.82% | # 18 |
