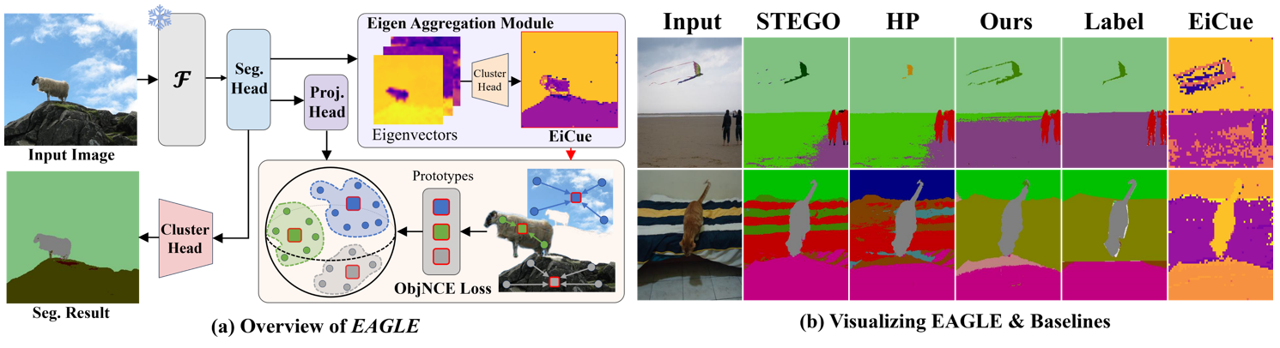
EAGLE: Eigen Aggregation Learning for Object-Centric Unsupervised Semantic Segmentation
Semantic segmentation has innately relied on extensive pixel-level annotated data, leading to the emergence of unsupervised methodologies. Among them, leveraging self-supervised Vision Transformers for unsupervised semantic segmentation (USS) has been making steady progress with expressive deep features. Yet, for semantically segmenting images with complex objects, a predominant challenge remains: the lack of explicit object-level semantic encoding in patch-level features. This technical limitation often leads to inadequate segmentation of complex objects with diverse structures. To address this gap, we present a novel approach, EAGLE, which emphasizes object-centric representation learning for unsupervised semantic segmentation. Specifically, we introduce EiCue, a spectral technique providing semantic and structural cues through an eigenbasis derived from the semantic similarity matrix of deep image features and color affinity from an image. Further, by incorporating our object-centric contrastive loss with EiCue, we guide our model to learn object-level representations with intra- and inter-image object-feature consistency, thereby enhancing semantic accuracy. Extensive experiments on COCO-Stuff, Cityscapes, and Potsdam-3 datasets demonstrate the state-of-the-art USS results of EAGLE with accurate and consistent semantic segmentation across complex scenes.
PDF AbstractCode






Datasets
 Cityscapes
Cityscapes
 COCO-Stuff
COCO-Stuff
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Unsupervised Semantic Segmentation | Cityscapes test | EAGLE (DINO, ViT-B/8) | mIoU | 22.1 | # 4 | |
| Accuracy | 79.4 | # 7 | ||||
| Unsupervised Semantic Segmentation | Cityscapes test | EAGLE (DINO, ViT-S/8) | mIoU | 19.7 | # 7 | |
| Accuracy | 81.8 | # 4 | ||||
| Unsupervised Semantic Segmentation | COCO-Stuff-27 | EAGLE (DINO, ViT-S/8) | Accuracy | 64.2 | # 4 | |
| mIoU | 27.2 | # 5 | ||||
| Unsupervised Semantic Segmentation | Potsdam-3 | EAGLE (DINO, ViT-B/8) | Accuracy | 83.3 | # 1 | |
| mIoU | 71.1 | # 1 |
