E2E-LOAD: End-to-End Long-form Online Action Detection
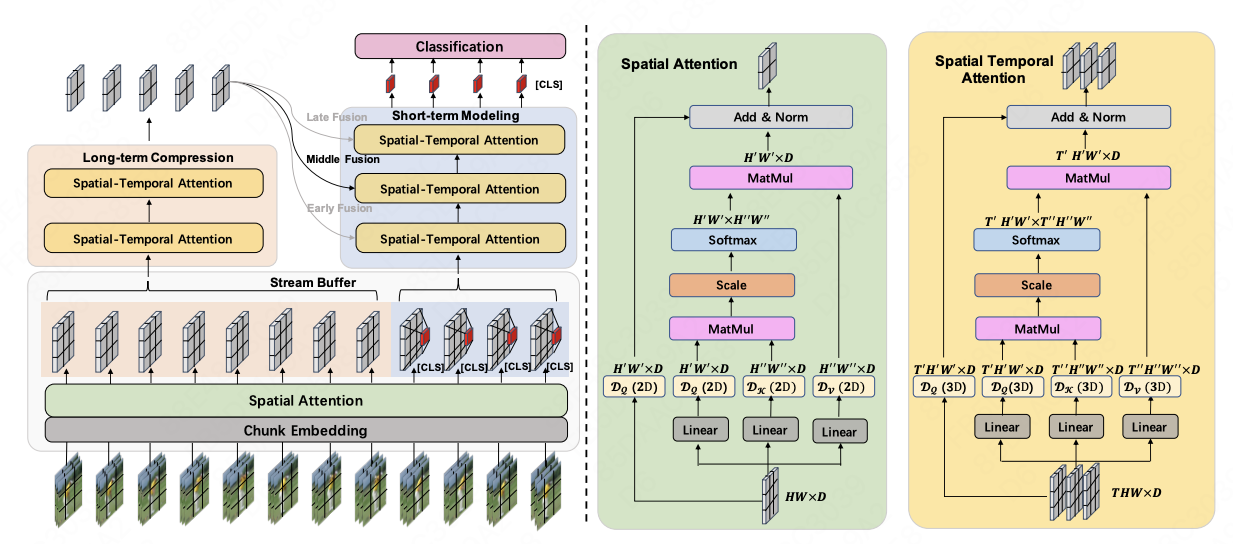
Recently, there has been a growing trend toward feature-based approaches for Online Action Detection (OAD). However, these approaches have limitations due to their fixed backbone design, which ignores the potential capability of a trainable backbone. In this paper, we propose the first end-to-end OAD model, termed E2E-LOAD, designed to address the major challenge of OAD, namely, long-term understanding and efficient online reasoning. Specifically, our proposed approach adopts an initial spatial model that is shared by all frames and maintains a long sequence cache for inference at a low computational cost. We also advocate an asymmetric spatial-temporal model for long-form and short-form modeling effectively. Furthermore, we propose a novel and efficient inference mechanism that accelerates heavy spatial-temporal exploration. Extensive ablation studies and experiments demonstrate the effectiveness and efficiency of our proposed method. Notably, we achieve 17.3 (+12.6) FPS for end-to-end OAD with 72.4%~(+1.2%), 90.3%~(+0.7%), and 48.1%~(+26.0%) mAP on THMOUS14, TVSeries, and HDD, respectively, which is 3x faster than previous approaches. The source code will be made publicly available.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract


 HDD
HDD
