Dynamic in Static: Hybrid Visual Correspondence for Self-Supervised Video Object Segmentation
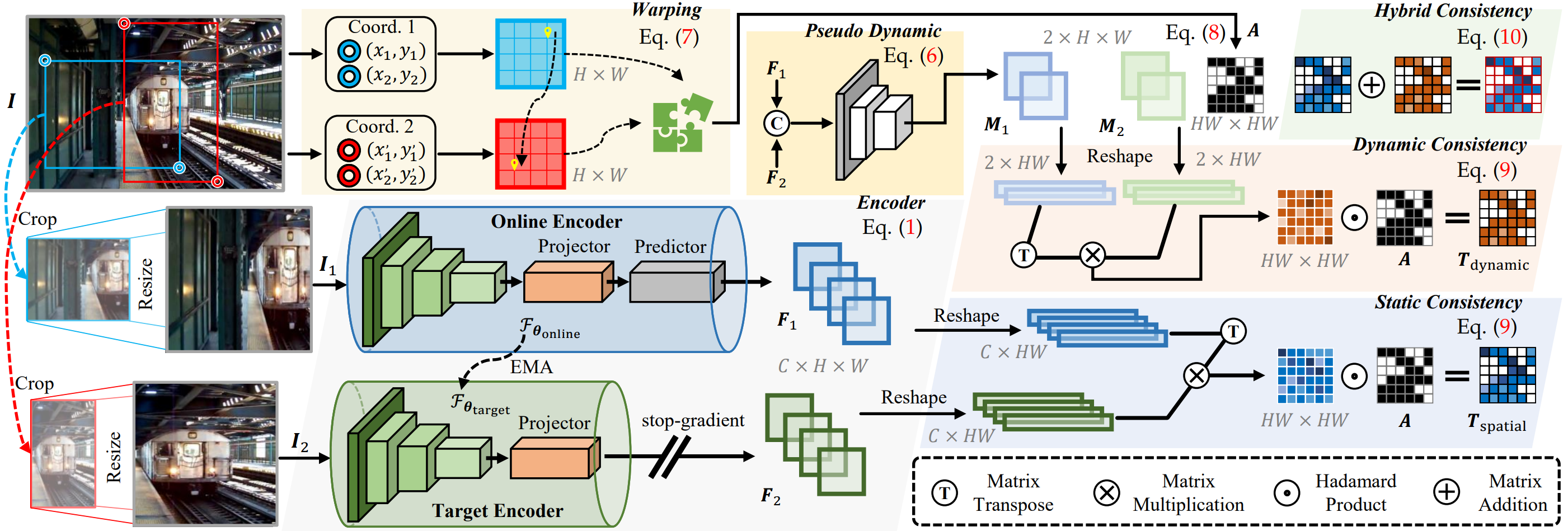
Conventional video object segmentation (VOS) methods usually necessitate a substantial volume of pixel-level annotated video data for fully supervised learning. In this paper, we present HVC, a \textbf{h}ybrid static-dynamic \textbf{v}isual \textbf{c}orrespondence framework for self-supervised VOS. HVC extracts pseudo-dynamic signals from static images, enabling an efficient and scalable VOS model. Our approach utilizes a minimalist fully-convolutional architecture to capture static-dynamic visual correspondence in image-cropped views. To achieve this objective, we present a unified self-supervised approach to learn visual representations of static-dynamic feature similarity. Firstly, we establish static correspondence by utilizing a priori coordinate information between cropped views to guide the formation of consistent static feature representations. Subsequently, we devise a concise convolutional layer to capture the forward / backward pseudo-dynamic signals between two views, serving as cues for dynamic representations. Finally, we propose a hybrid visual correspondence loss to learn joint static and dynamic consistency representations. Our approach, without bells and whistles, necessitates only one training session using static image data, significantly reducing memory consumption ($\sim$16GB) and training time ($\sim$\textbf{2h}). Moreover, HVC achieves state-of-the-art performance in several self-supervised VOS benchmarks and additional video label propagation tasks.
PDF Abstract



 ImageNet
ImageNet
 MS COCO
MS COCO
 DAVIS
DAVIS
 JHMDB
JHMDB
 VOST
VOST
