DVIS++: Improved Decoupled Framework for Universal Video Segmentation
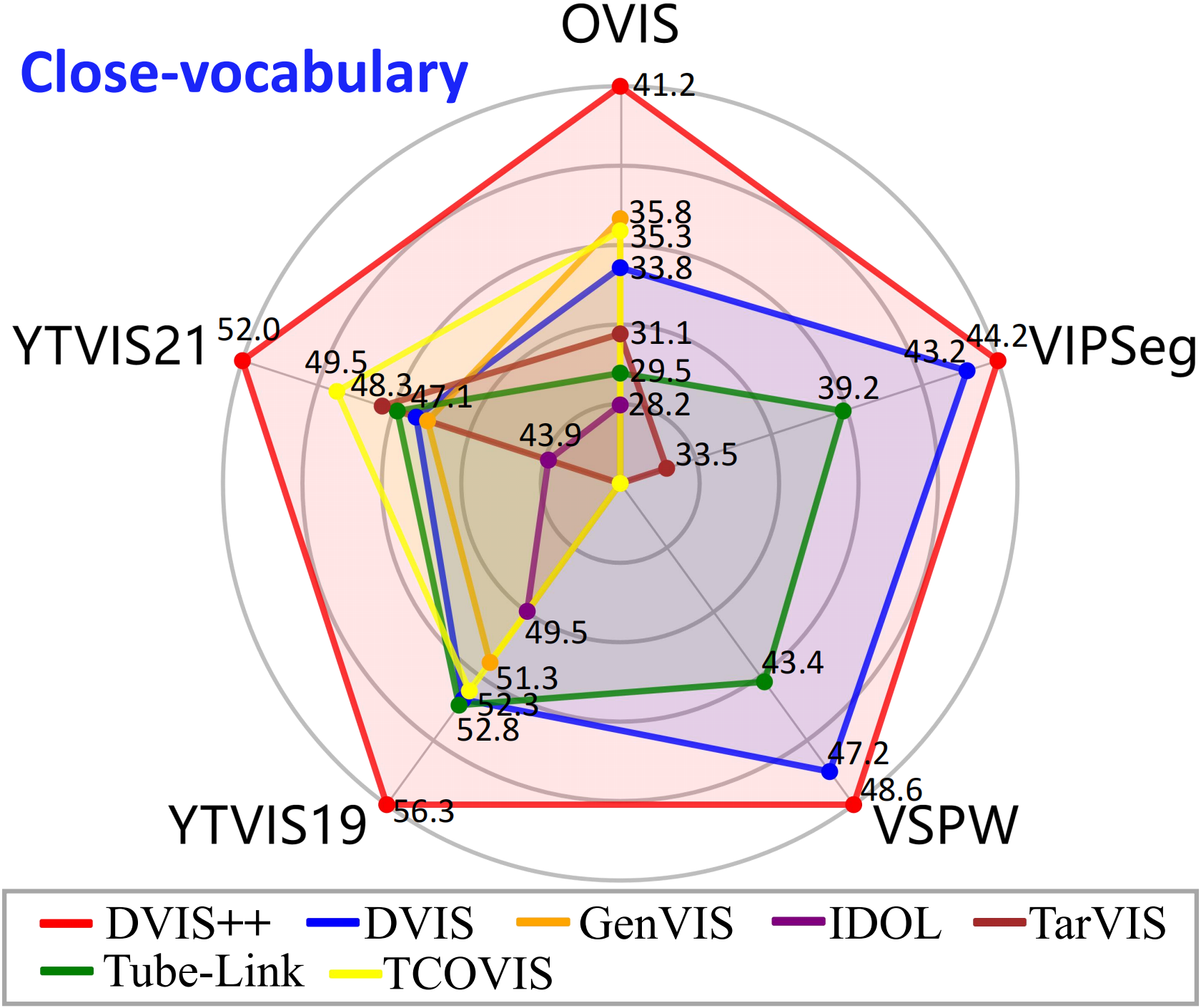
We present the \textbf{D}ecoupled \textbf{VI}deo \textbf{S}egmentation (DVIS) framework, a novel approach for the challenging task of universal video segmentation, including video instance segmentation (VIS), video semantic segmentation (VSS), and video panoptic segmentation (VPS). Unlike previous methods that model video segmentation in an end-to-end manner, our approach decouples video segmentation into three cascaded sub-tasks: segmentation, tracking, and refinement. This decoupling design allows for simpler and more effective modeling of the spatio-temporal representations of objects, especially in complex scenes and long videos. Accordingly, we introduce two novel components: the referring tracker and the temporal refiner. These components track objects frame by frame and model spatio-temporal representations based on pre-aligned features. To improve the tracking capability of DVIS, we propose a denoising training strategy and introduce contrastive learning, resulting in a more robust framework named DVIS++. Furthermore, we evaluate DVIS++ in various settings, including open vocabulary and using a frozen pre-trained backbone. By integrating CLIP with DVIS++, we present OV-DVIS++, the first open-vocabulary universal video segmentation framework. We conduct extensive experiments on six mainstream benchmarks, including the VIS, VSS, and VPS datasets. Using a unified architecture, DVIS++ significantly outperforms state-of-the-art specialized methods on these benchmarks in both close- and open-vocabulary settings. Code:~\url{https://github.com/zhang-tao-whu/DVIS_Plus}.
PDF AbstractCode








 MS COCO
MS COCO
 LVIS
LVIS
 YouTube-VIS 2019
YouTube-VIS 2019
 OVIS
OVIS
 Youtube-VIS 2022 Validation
Youtube-VIS 2022 Validation

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Video Instance Segmentation | OVIS validation | DVIS++(VIT-L, Offline) | mask AP | 53.4 | # 1 | ||
| AP50 | 78.9 | # 1 | |||||
| AP75 | 58.5 | # 1 | |||||
| AR1 | 21.1 | # 1 | |||||
| AR10 | 58.7 | # 1 | |||||
| APso | 70.4 | # 1 | |||||
| APmo | 59.8 | # 1 | |||||
| APho | 32.9 | # 1 | |||||
| Video Instance Segmentation | OVIS validation | DVIS++(VIT-L, Online) | mask AP | 49.6 | # 4 | ||
| AP50 | 72.5 | # 3 | |||||
| AP75 | 55.0 | # 3 | |||||
| AR1 | 20.8 | # 2 | |||||
| AR10 | 54.6 | # 3 | |||||
| APso | 69.9 | # 2 | |||||
| APmo | 56.6 | # 2 | |||||
| APho | 27.1 | # 2 | |||||
| Video Instance Segmentation | OVIS validation | DVIS++(R50, Offline) | mask AP | 41.2 | # 17 | ||
| AP50 | 68.9 | # 10 | |||||
| AP75 | 40.9 | # 17 | |||||
| AR1 | 16.8 | # 14 | |||||
| AR10 | 47.3 | # 11 | |||||
| Video Instance Segmentation | OVIS validation | DVIS++(R50, Online) | mask AP | 37.2 | # 20 | ||
| AP50 | 62.8 | # 17 | |||||
| AP75 | 37.3 | # 20 | |||||
| AR1 | 15.8 | # 19 | |||||
| AR10 | 42.9 | # 15 | |||||
| Video Panoptic Segmentation | VIPSeg | DVIS++(VIT-L) | VPQ | 58.0 | # 1 | ||
| STQ | 56.0 | # 2 | |||||
| Video Semantic Segmentation | VSPW | DVIS++(VIT-L) | mIoU | 63.8 | # 1 | ||
| Video Instance Segmentation | YouTube-VIS 2021 | DVIS++(VIT-L, Offline) | mask AP | 63.9 | # 1 | ||
| AP50 | 86.7 | # 1 | |||||
| AP75 | 71.5 | # 1 | |||||
| AR10 | 69.5 | # 1 | |||||
| AR1 | 48.8 | # 3 | |||||
| Video Instance Segmentation | YouTube-VIS 2021 | DVIS++(VIT-L, Online) | mask AP | 62.3 | # 2 | ||
| AP50 | 82.7 | # 4 | |||||
| AP75 | 70.2 | # 2 | |||||
| AR10 | 68.0 | # 2 | |||||
| AR1 | 49.5 | # 1 | |||||
| Video Instance Segmentation | Youtube-VIS 2022 Validation | DVIS++(VIT-L) | mAP_L | 50.9 | # 1 | ||
| AP50_L | 75.7 | # 1 | |||||
| AP75_L | 52.8 | # 1 | |||||
| AR1_L | 40.6 | # 1 | |||||
| AR10_L | 55.8 | # 1 | |||||
| Video Instance Segmentation | YouTube-VIS validation | DVIS++(VIT-L, Offline) | mask AP | 68.3 | # 1 | ||
| AP50 | 90.3 | # 1 | |||||
| AP75 | 76.1 | # 1 | |||||
| AR1 | 57.8 | # 2 | |||||
| AR10 | 73.4 | # 2 | |||||
| Video Instance Segmentation | YouTube-VIS validation | DVIS++(VIT-L, Online) | mask AP | 67.7 | # 2 | ||
| AP50 | 88.8 | # 2 | |||||
| AP75 | 75.3 | # 2 | |||||
| AR1 | 57.9 | # 1 | |||||
| AR10 | 73.7 | # 1 |
