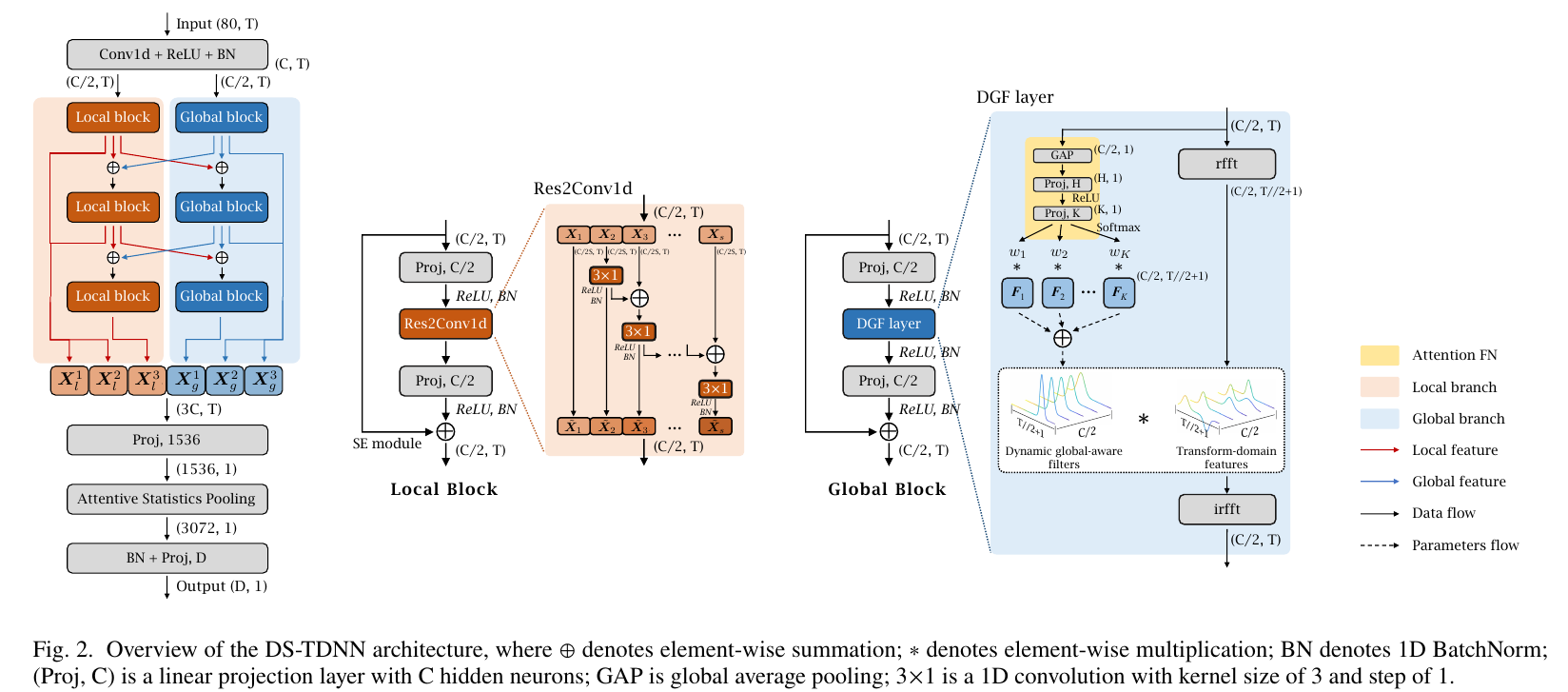
DS-TDNN: Dual-stream Time-delay Neural Network with Global-aware Filter for Speaker Verification
Conventional time-delay neural networks (TDNNs) struggle to handle long-range context, their ability to represent speaker information is therefore limited in long utterances. Existing solutions either depend on increasing model complexity or try to balance between local features and global context to address this issue. To effectively leverage the long-term dependencies of audio signals and constrain model complexity, we introduce a novel module called Global-aware Filter layer (GF layer) in this work, which employs a set of learnable transform-domain filters between a 1D discrete Fourier transform and its inverse transform to capture global context. Additionally, we develop a dynamic filtering strategy and a sparse regularization method to enhance the performance of the GF layer and prevent overfitting. Based on the GF layer, we present a dual-stream TDNN architecture called DS-TDNN for automatic speaker verification (ASV), which utilizes two unique branches to extract both local and global features in parallel and employs an efficient strategy to fuse different-scale information. Experiments on the Voxceleb and SITW databases demonstrate that the DS-TDNN achieves a relative improvement of 10\% together with a relative decline of 20\% in computational cost over the ECAPA-TDNN in speaker verification task. This improvement will become more evident as the utterance's duration grows. Furthermore, the DS-TDNN also beats popular deep residual models and attention-based systems on utterances of arbitrary length.
PDF Abstract


 VoxCeleb1
VoxCeleb1
 VoxCeleb2
VoxCeleb2
