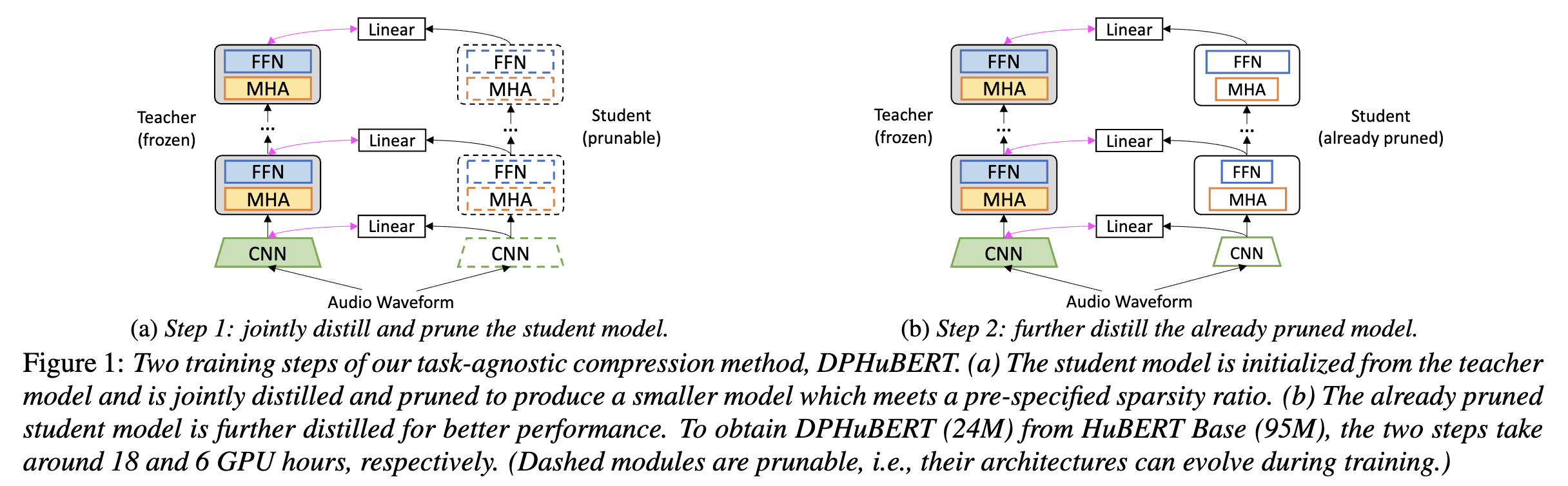
DPHuBERT: Joint Distillation and Pruning of Self-Supervised Speech Models
Self-supervised learning (SSL) has achieved notable success in many speech processing tasks, but the large model size and heavy computational cost hinder the deployment. Knowledge distillation trains a small student model to mimic the behavior of a large teacher model. However, the student architecture usually needs to be manually designed and will remain fixed during training, which requires prior knowledge and can lead to suboptimal performance. Inspired by recent success of task-specific structured pruning, we propose DPHuBERT, a novel task-agnostic compression method for speech SSL based on joint distillation and pruning. Experiments on SUPERB show that DPHuBERT outperforms pure distillation methods in almost all tasks. Moreover, DPHuBERT requires little training time and performs well with limited training data, making it suitable for resource-constrained applications. Our method can also be applied to various speech SSL models. Our code and models will be publicly available.
PDF Abstract


 LibriSpeech
LibriSpeech
