DORA: Exploring Outlier Representations in Deep Neural Networks
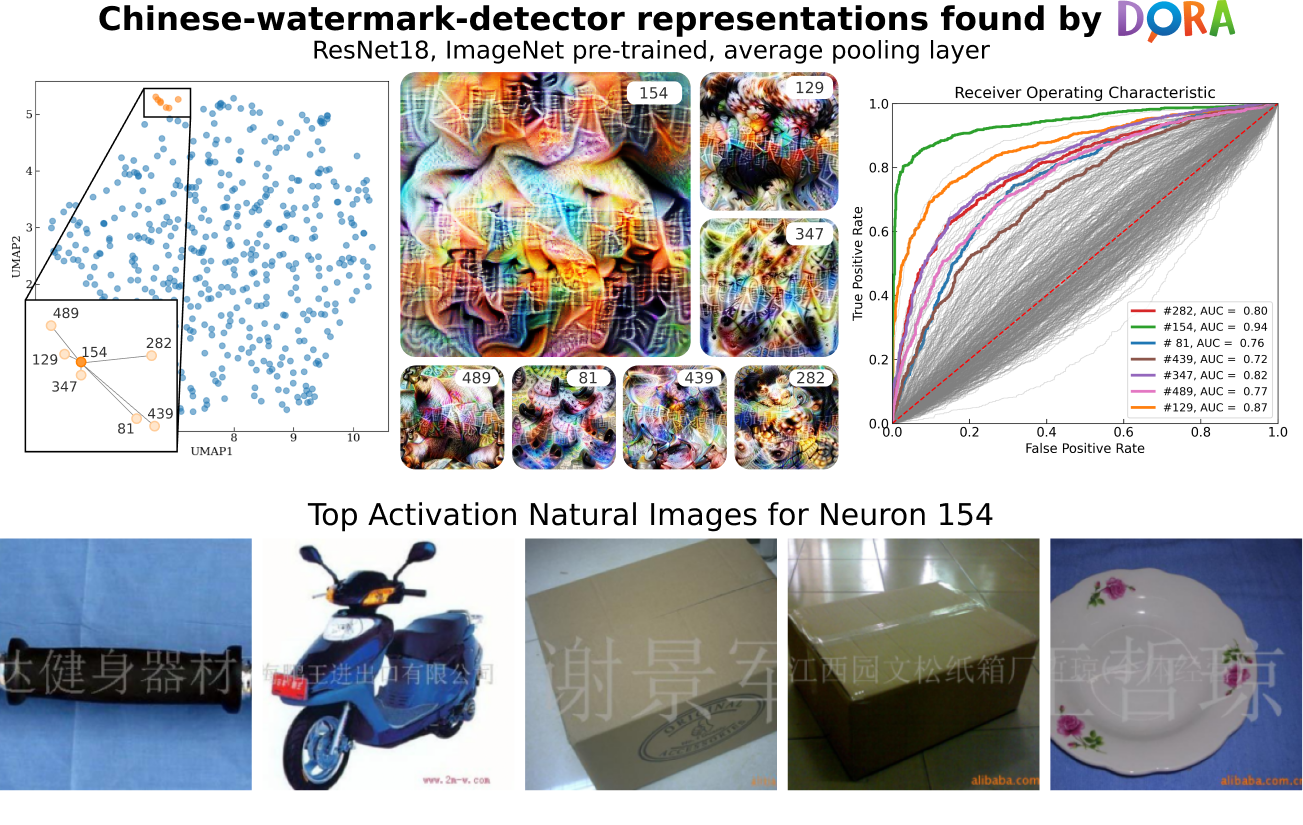
Deep Neural Networks (DNNs) excel at learning complex abstractions within their internal representations. However, the concepts they learn remain opaque, a problem that becomes particularly acute when models unintentionally learn spurious correlations. In this work, we present DORA (Data-agnOstic Representation Analysis), the first data-agnostic framework for analyzing the representational space of DNNs. Central to our framework is the proposed Extreme-Activation (EA) distance measure, which assesses similarities between representations by analyzing their activation patterns on data points that cause the highest level of activation. As spurious correlations often manifest in features of data that are anomalous to the desired task, such as watermarks or artifacts, we demonstrate that internal representations capable of detecting such artifactual concepts can be found by analyzing relationships within neural representations. We validate the EA metric quantitatively, demonstrating its effectiveness both in controlled scenarios and real-world applications. Finally, we provide practical examples from popular Computer Vision models to illustrate that representations identified as outliers using the EA metric often correspond to undesired and spurious concepts.
PDF Abstract Colab
Colab


 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 Tiny ImageNet
Tiny ImageNet
