Don't Trust: Verify -- Grounding LLM Quantitative Reasoning with Autoformalization
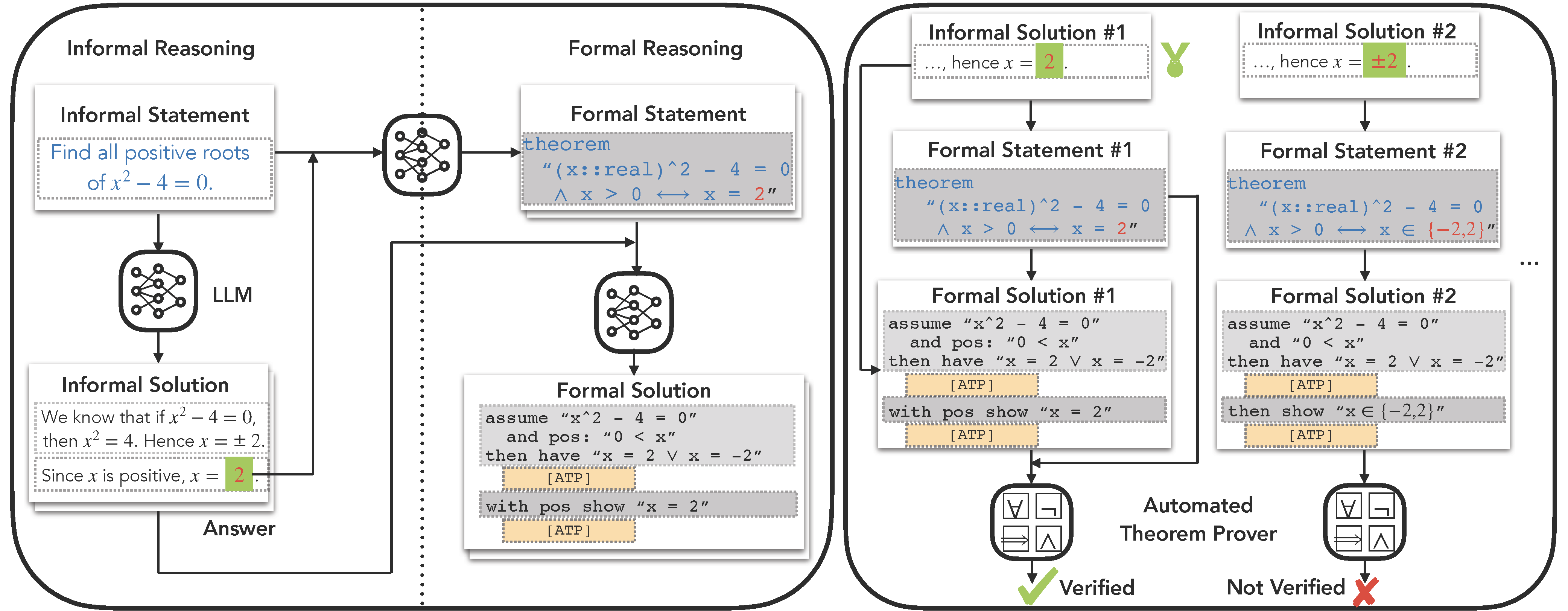
Large language models (LLM), such as Google's Minerva and OpenAI's GPT families, are becoming increasingly capable of solving mathematical quantitative reasoning problems. However, they still make unjustified logical and computational errors in their reasoning steps and answers. In this paper, we leverage the fact that if the training corpus of LLMs contained sufficiently many examples of formal mathematics (e.g. in Isabelle, a formal theorem proving environment), they can be prompted to translate i.e. autoformalize informal mathematical statements into formal Isabelle code -- which can be verified automatically for internal consistency. This provides a mechanism to automatically reject solutions whose formalized versions are inconsistent within themselves or with the formalized problem statement. We evaluate our method on GSM8K, MATH and MultiArith datasets and demonstrate that our approach provides a consistently better heuristic than vanilla majority voting -- the previously best method to identify correct answers, by more than 12% on GSM8K. In our experiments it improves results consistently across all datasets and LLM model sizes. The code can be found at https://github.com/jinpz/dtv.
PDF Abstract
 GSM8K
GSM8K
 MATH
MATH
