Do We Actually Need Dense Over-Parameterization? In-Time Over-Parameterization in Sparse Training
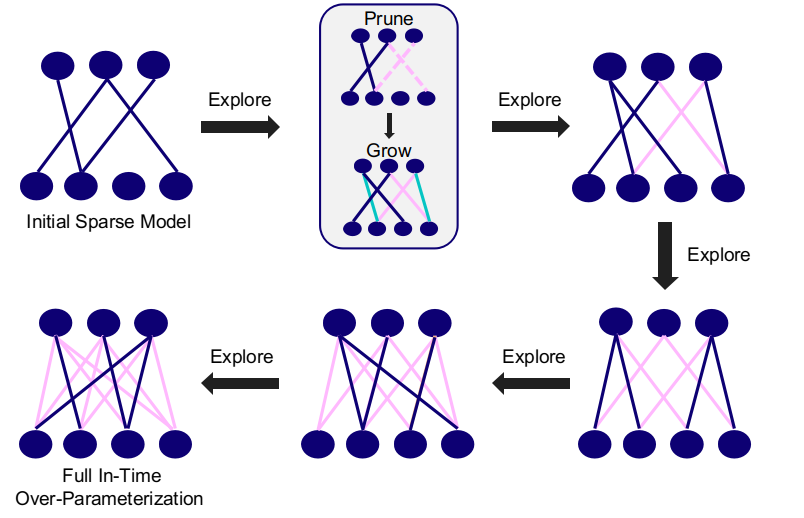
In this paper, we introduce a new perspective on training deep neural networks capable of state-of-the-art performance without the need for the expensive over-parameterization by proposing the concept of In-Time Over-Parameterization (ITOP) in sparse training. By starting from a random sparse network and continuously exploring sparse connectivities during training, we can perform an Over-Parameterization in the space-time manifold, closing the gap in the expressibility between sparse training and dense training. We further use ITOP to understand the underlying mechanism of Dynamic Sparse Training (DST) and indicate that the benefits of DST come from its ability to consider across time all possible parameters when searching for the optimal sparse connectivity. As long as there are sufficient parameters that have been reliably explored during training, DST can outperform the dense neural network by a large margin. We present a series of experiments to support our conjecture and achieve the state-of-the-art sparse training performance with ResNet-50 on ImageNet. More impressively, our method achieves dominant performance over the overparameterization-based sparse methods at extreme sparsity levels. When trained on CIFAR-100, our method can match the performance of the dense model even at an extreme sparsity (98%). Code can be found https://github.com/Shiweiliuiiiiiii/In-Time-Over-Parameterization.
PDF Abstract


 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100

