Do VSR Models Generalize Beyond LRS3?
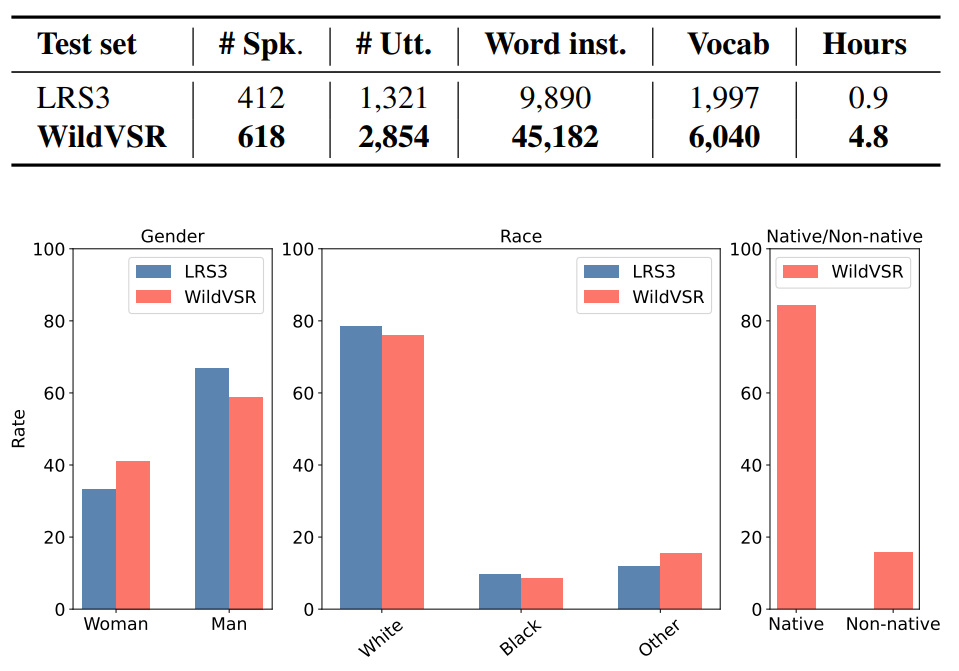
The Lip Reading Sentences-3 (LRS3) benchmark has primarily been the focus of intense research in visual speech recognition (VSR) during the last few years. As a result, there is an increased risk of overfitting to its excessively used test set, which is only one hour duration. To alleviate this issue, we build a new VSR test set named WildVSR, by closely following the LRS3 dataset creation processes. We then evaluate and analyse the extent to which the current VSR models generalize to the new test data. We evaluate a broad range of publicly available VSR models and find significant drops in performance on our test set, compared to their corresponding LRS3 results. Our results suggest that the increase in word error rates is caused by the models inability to generalize to slightly harder and in the wild lip sequences than those found in the LRS3 test set. Our new test benchmark is made public in order to enable future research towards more robust VSR models.
PDF Abstract


 VoxCeleb2
VoxCeleb2
 LRW
LRW
 LRS2
LRS2
