Distance approximation using Isolation Forests
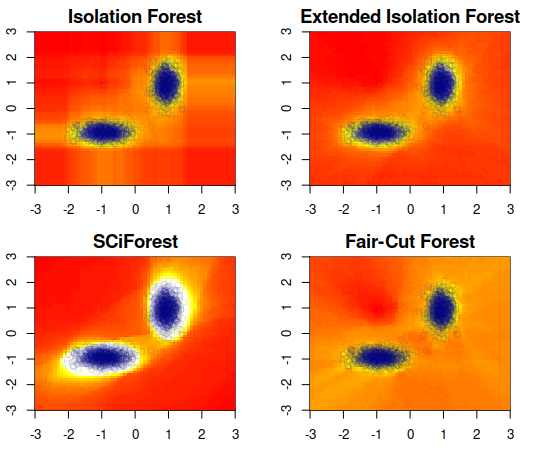
This work briefly explores the possibility of approximating spatial distance (alternatively, similarity) between data points using the Isolation Forest method envisioned for outlier detection. The logic is similar to that of isolation: the more similar or closer two points are, the more random splits it will take to separate them. The separation depth between two points can be standardized in the same way as the isolation depth, transforming it into a distance metric that is limited in range, centered, and in compliance with the axioms of distance. This metric presents some desirable properties such as being invariant to the scales of variables or being able to account for non-linear relationships between variables, which other metrics such as Euclidean or Mahalanobis distance do not. Extensions to the Isolation Forest method are also proposed for handling categorical variables and missing values, resulting in a more generalizable and robust metric.
PDF Abstract
