Dissecting Adam: The Sign, Magnitude and Variance of Stochastic Gradients
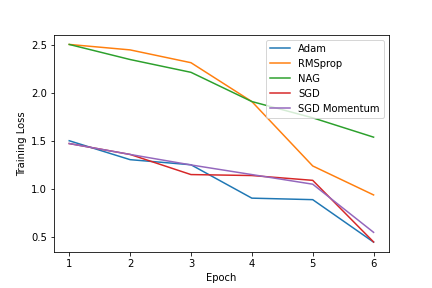
The ADAM optimizer is exceedingly popular in the deep learning community. Often it works very well, sometimes it doesn't. Why? We interpret ADAM as a combination of two aspects: for each weight, the update direction is determined by the sign of stochastic gradients, whereas the update magnitude is determined by an estimate of their relative variance. We disentangle these two aspects and analyze them in isolation, gaining insight into the mechanisms underlying ADAM. This analysis also extends recent results on adverse effects of ADAM on generalization, isolating the sign aspect as the problematic one. Transferring the variance adaptation to SGD gives rise to a novel method, completing the practitioner's toolbox for problems where ADAM fails.
PDF Abstract ICML 2018 PDF ICML 2018 Abstract

 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 Fashion-MNIST
Fashion-MNIST
