Disentangling Policy from Offline Task Representation Learning via Adversarial Data Augmentation
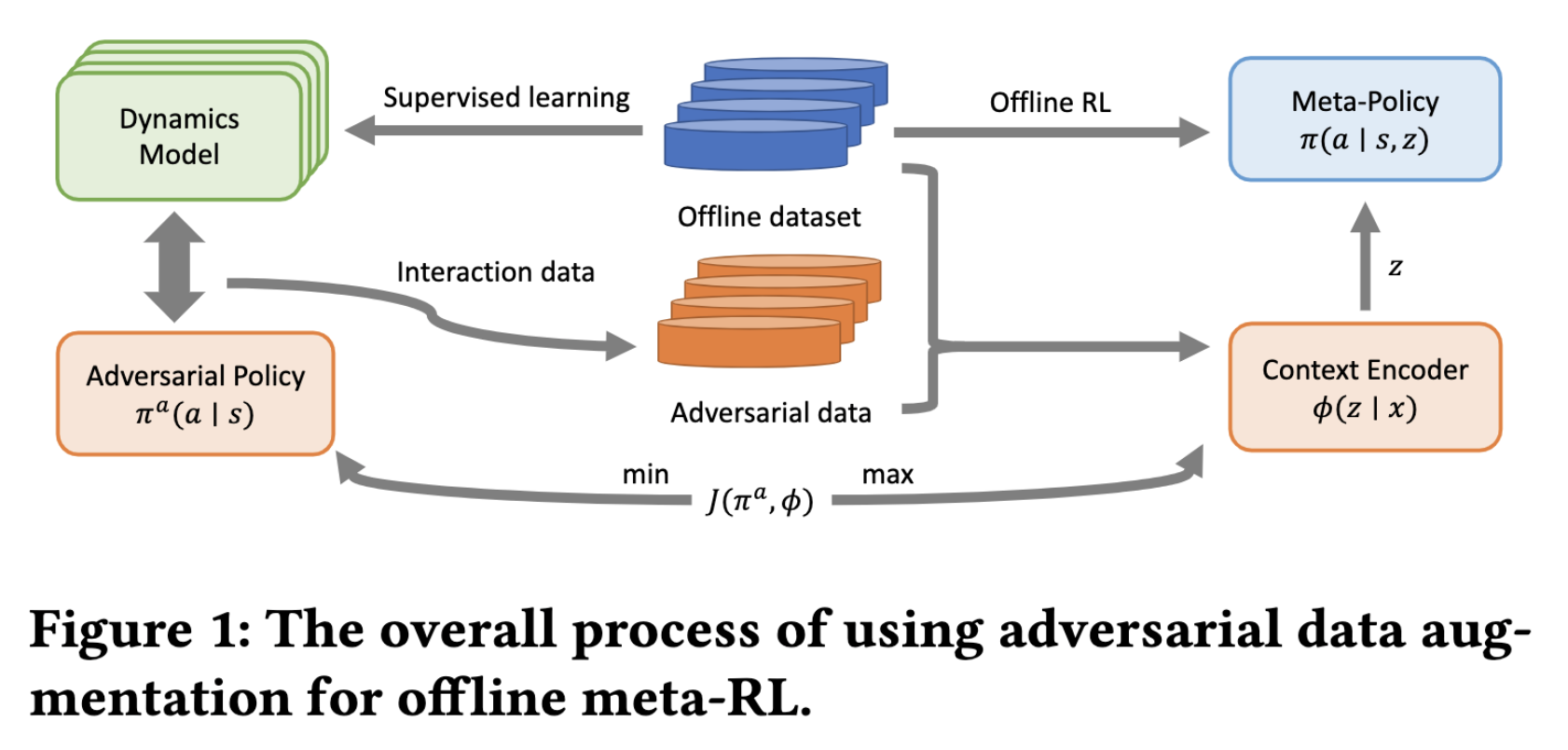
Offline meta-reinforcement learning (OMRL) proficiently allows an agent to tackle novel tasks while solely relying on a static dataset. For precise and efficient task identification, existing OMRL research suggests learning separate task representations that be incorporated with policy input, thus forming a context-based meta-policy. A major approach to train task representations is to adopt contrastive learning using multi-task offline data. The dataset typically encompasses interactions from various policies (i.e., the behavior policies), thus providing a plethora of contextual information regarding different tasks. Nonetheless, amassing data from a substantial number of policies is not only impractical but also often unattainable in realistic settings. Instead, we resort to a more constrained yet practical scenario, where multi-task data collection occurs with a limited number of policies. We observed that learned task representations from previous OMRL methods tend to correlate spuriously with the behavior policy instead of reflecting the essential characteristics of the task, resulting in unfavorable out-of-distribution generalization. To alleviate this issue, we introduce a novel algorithm to disentangle the impact of behavior policy from task representation learning through a process called adversarial data augmentation. Specifically, the objective of adversarial data augmentation is not merely to generate data analogous to offline data distribution; instead, it aims to create adversarial examples designed to confound learned task representations and lead to incorrect task identification. Our experiments show that learning from such adversarial samples significantly enhances the robustness and effectiveness of the task identification process and realizes satisfactory out-of-distribution generalization.
PDF Abstract




 MuJoCo
MuJoCo
