DisCont: Self-Supervised Visual Attribute Disentanglement using Context Vectors
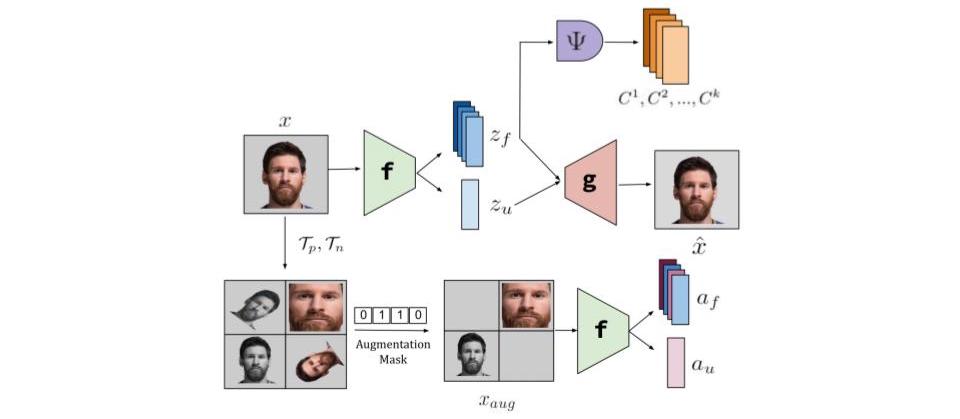
Disentangling the underlying feature attributes within an image with no prior supervision is a challenging task. Models that can disentangle attributes well provide greater interpretability and control. In this paper, we propose a self-supervised framework DisCont to disentangle multiple attributes by exploiting the structural inductive biases within images. Motivated by the recent surge in contrastive learning paradigms, our model bridges the gap between self-supervised contrastive learning algorithms and unsupervised disentanglement. We evaluate the efficacy of our approach, both qualitatively and quantitatively, on four benchmark datasets.
PDF Abstract


Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
