DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion
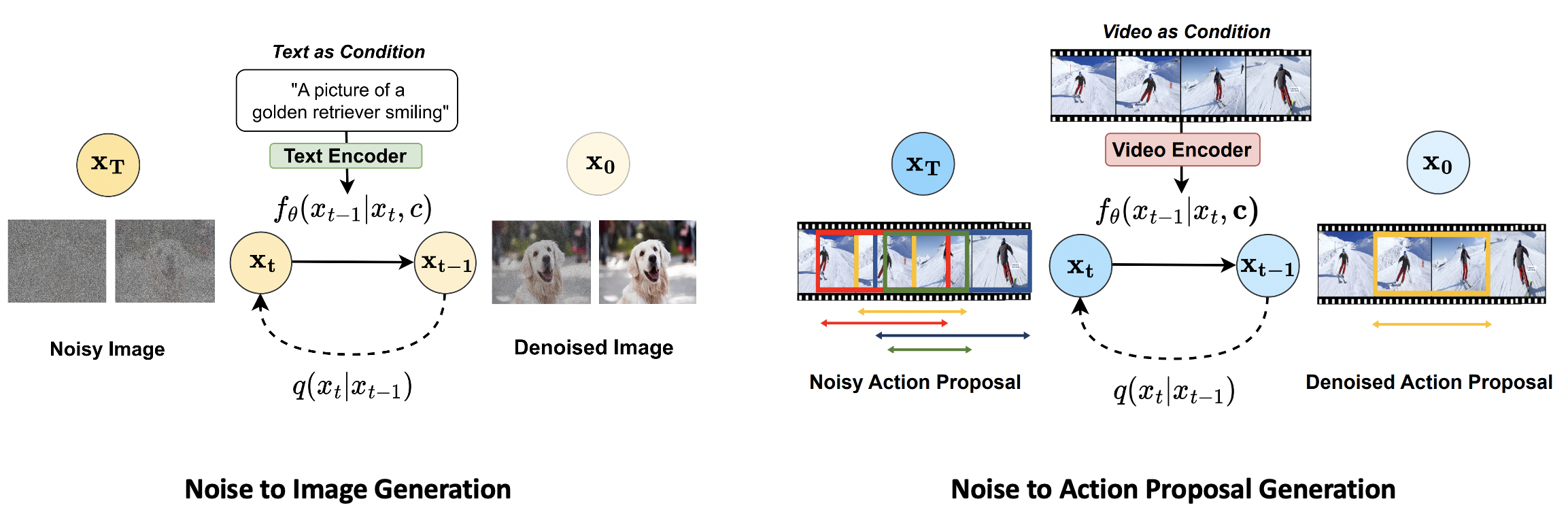
We propose a new formulation of temporal action detection (TAD) with denoising diffusion, DiffTAD in short. Taking as input random temporal proposals, it can yield action proposals accurately given an untrimmed long video. This presents a generative modeling perspective, against previous discriminative learning manners. This capability is achieved by first diffusing the ground-truth proposals to random ones (i.e., the forward/noising process) and then learning to reverse the noising process (i.e., the backward/denoising process). Concretely, we establish the denoising process in the Transformer decoder (e.g., DETR) by introducing a temporal location query design with faster convergence in training. We further propose a cross-step selective conditioning algorithm for inference acceleration. Extensive evaluations on ActivityNet and THUMOS show that our DiffTAD achieves top performance compared to previous art alternatives. The code will be made available at https://github.com/sauradip/DiffusionTAD.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract


 ActivityNet
ActivityNet
