Differentially Private Next-Token Prediction of Large Language Models
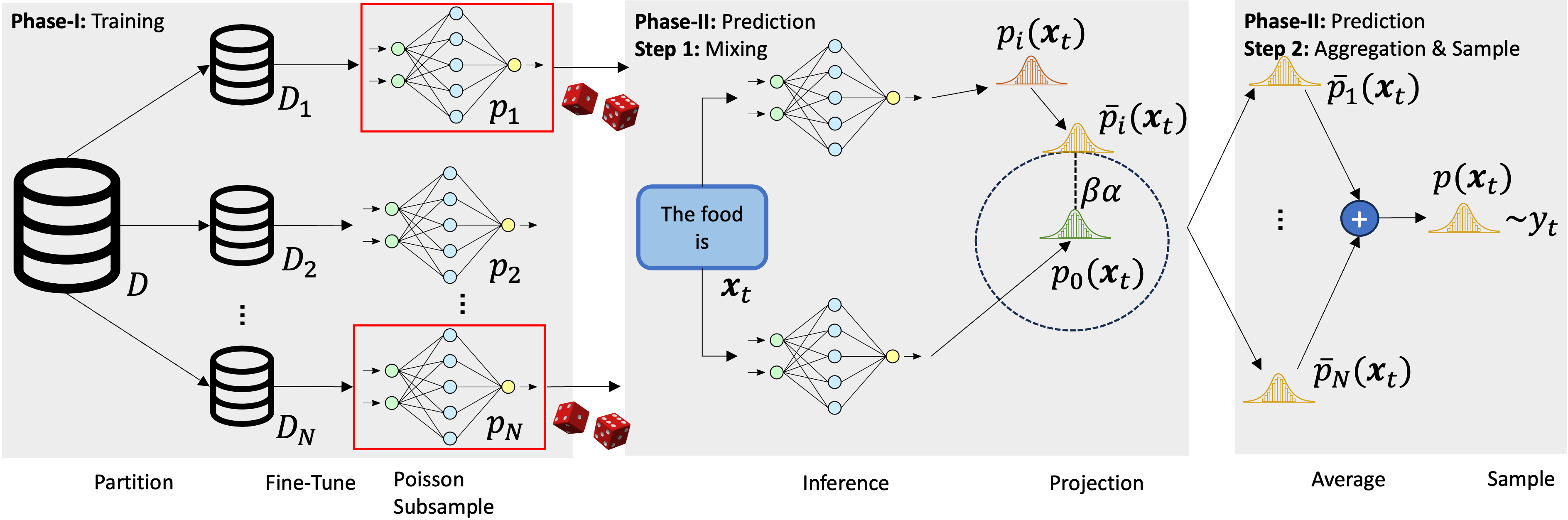
Ensuring the privacy of Large Language Models (LLMs) is becoming increasingly important. The most widely adopted technique to accomplish this is DP-SGD, which trains a model to guarantee Differential Privacy (DP). However, DP-SGD overestimates an adversary's capabilities in having white box access to the model and, as a result, causes longer training times and larger memory usage than SGD. On the other hand, commercial LLM deployments are predominantly cloud-based; hence, adversarial access to LLMs is black-box. Motivated by these observations, we present Private Mixing of Ensemble Distributions (PMixED): a private prediction protocol for next-token prediction that utilizes the inherent stochasticity of next-token sampling and a public model to achieve Differential Privacy. We formalize this by introducing RD-mollifers which project each of the model's output distribution from an ensemble of fine-tuned LLMs onto a set around a public LLM's output distribution, then average the projected distributions and sample from it. Unlike DP-SGD which needs to consider the model architecture during training, PMixED is model agnostic, which makes PMixED a very appealing solution for current deployments. Our results show that PMixED achieves a stronger privacy guarantee than sample-level privacy and outperforms DP-SGD for privacy $\epsilon = 8$ on large-scale datasets. Thus, PMixED offers a practical alternative to DP training methods for achieving strong generative utility without compromising privacy.
PDF Abstract
 WikiText-2
WikiText-2
 WikiText-103
WikiText-103
