Differentiable Data Augmentation for Contrastive Sentence Representation Learning
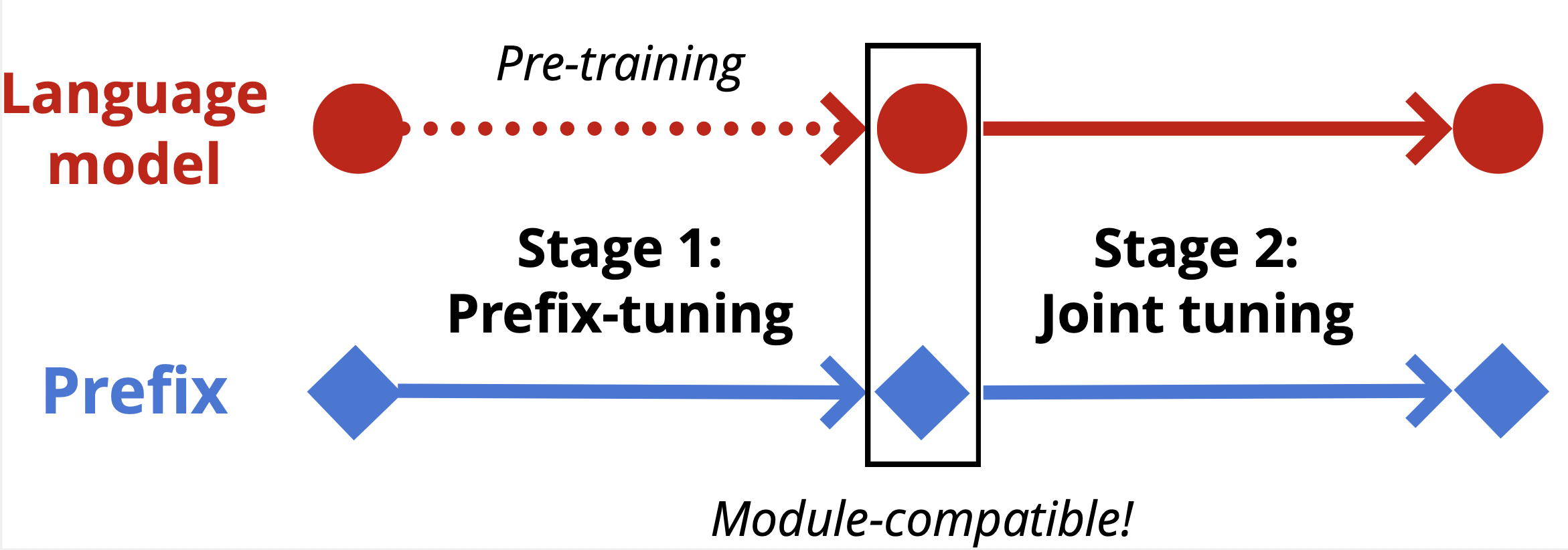
Fine-tuning a pre-trained language model via the contrastive learning framework with a large amount of unlabeled sentences or labeled sentence pairs is a common way to obtain high-quality sentence representations. Although the contrastive learning framework has shown its superiority on sentence representation learning over previous methods, the potential of such a framework is under-explored so far due to the simple method it used to construct positive pairs. Motivated by this, we propose a method that makes hard positives from the original training examples. A pivotal ingredient of our approach is the use of prefix that is attached to a pre-trained language model, which allows for differentiable data augmentation during contrastive learning. Our method can be summarized in two steps: supervised prefix-tuning followed by joint contrastive fine-tuning with unlabeled or labeled examples. Our experiments confirm the effectiveness of our data augmentation approach. The proposed method yields significant improvements over existing methods under both semi-supervised and supervised settings. Our experiments under a low labeled data setting also show that our method is more label-efficient than the state-of-the-art contrastive learning methods.
PDF Abstract





